How does it work?¶
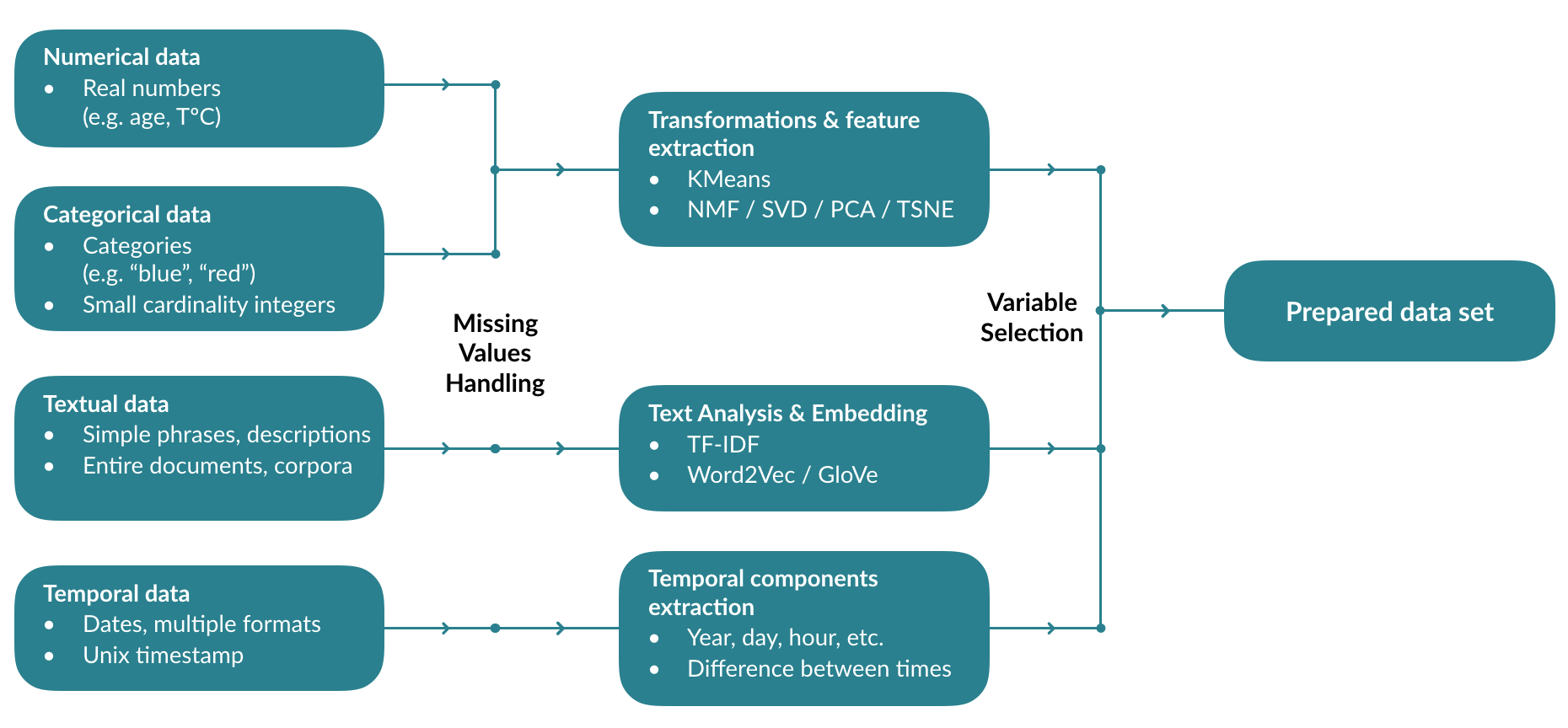
The first step that the platform will perform is a data transformation. The types (Numeric, Text, Date, etc.) of the different columns will be detected, and specific transformations will be applied to them.
Numerical & categorical variables:
- Unsupervised clustering (K-Means)
- Non-negative matrix factorization
- Singular Value Decomposition
- Principal Component Analysis
- Stochastic Neighbor Embedding (T-SNE)
Text variables:
- Statistical analysis (TF-IDF)
- Embedding (Word2Vec & GloVe)
Time data:
- Extraction of components (Year, day, time, etc.)
- Distances (durations) between data set dates
Depending on the problem, missing values will be processed differently, imputed if possible, or encoded in a specific way.
All transformed features will be evaluated and selected to create the data set used for the training.
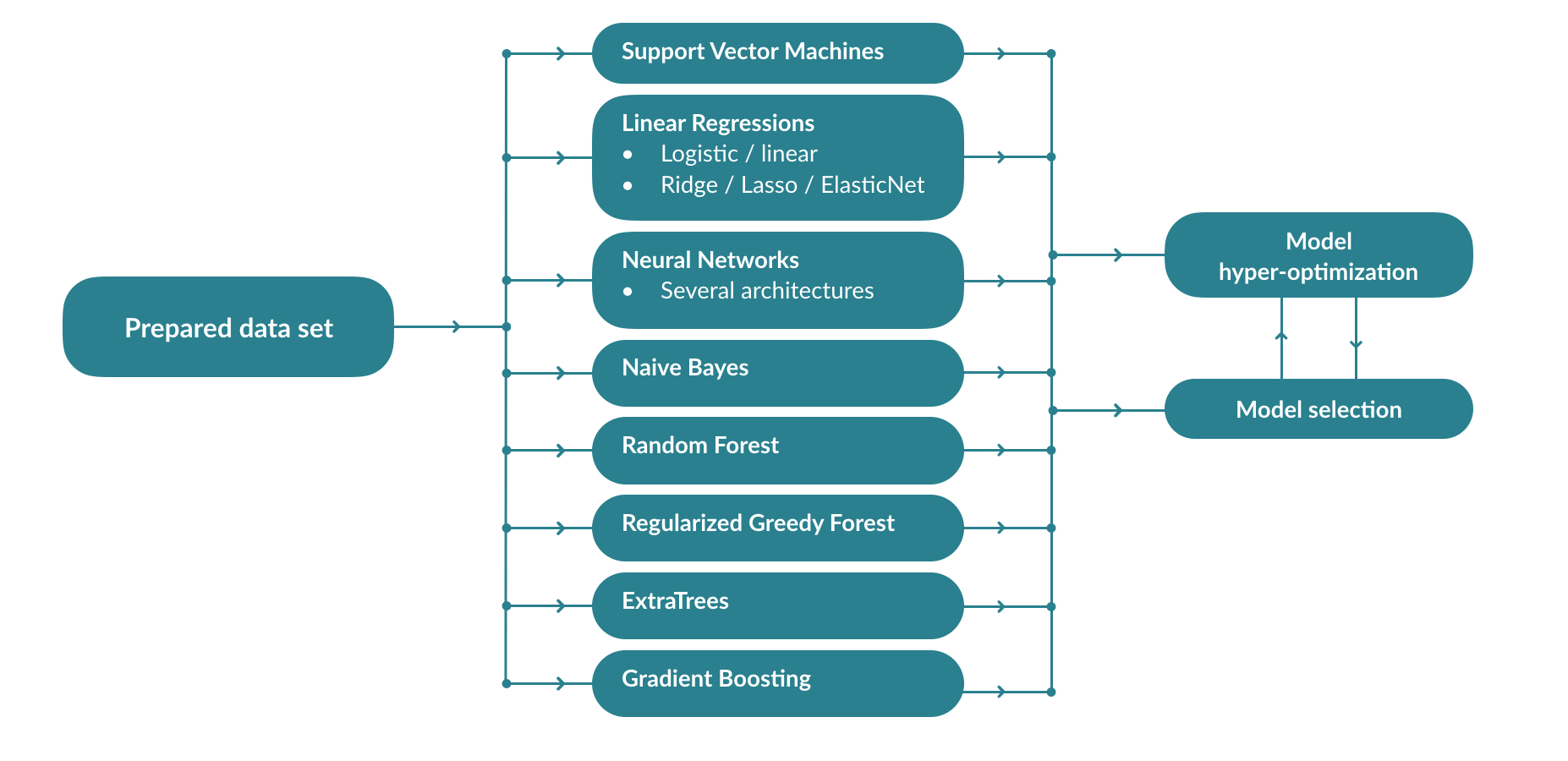
Model training¶
From the transformed dataset, a collection of models will be trained, and their optimal hyper-parameters will be optimized. To avoid the combinatorial explosion that would result from the « brute-force » optimization of all algorithms and their hyper-parameters, the Previsision.io engine learns the right combinations of models and parameters according to the data set and the type of problem in order to rapidly train the best models
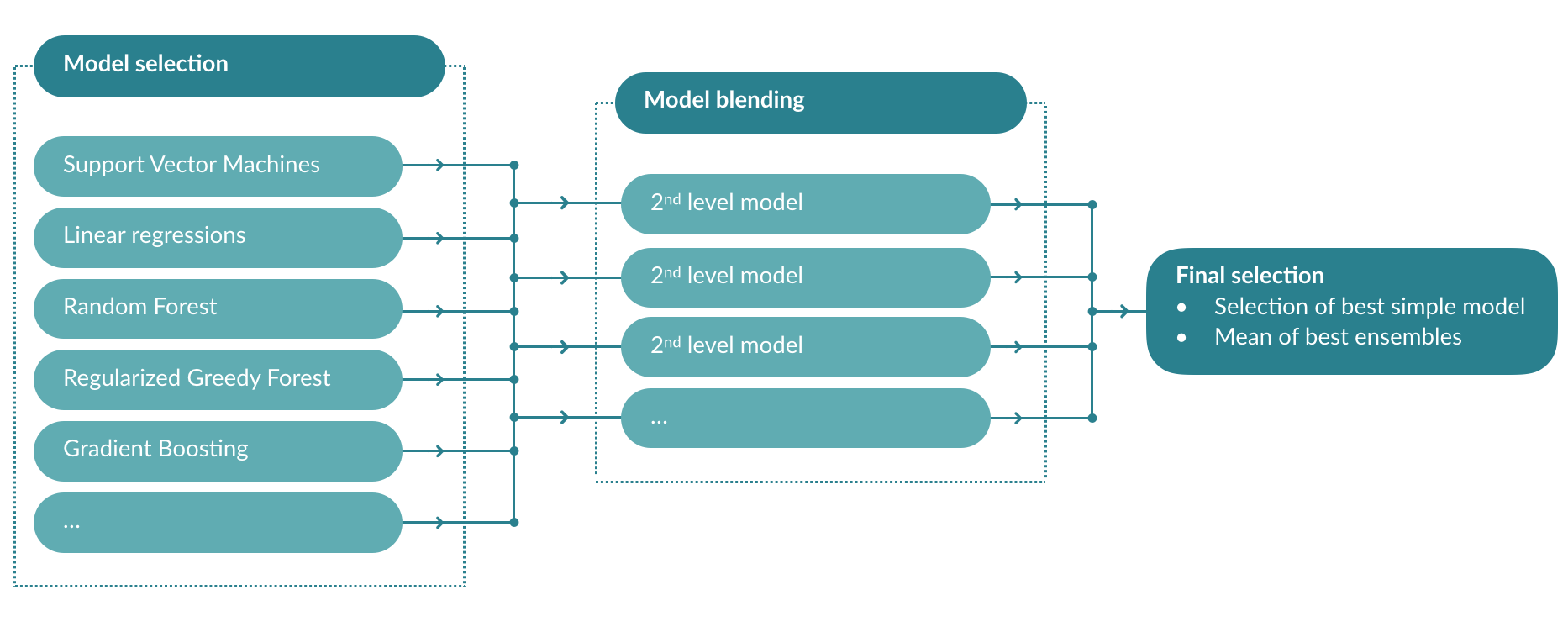
Ensemble learning¶
Once a series of models have been trained, the platform will train a second level of models using the predictions of the first as input data. This makes it possible to compensate for the errors of the different models and to provide more stable and accurate predictions.
The average of the predictions of the second-level models is taken to maximize the stability of the predictions. The cross-validation system avoids the leakage of information across the different models and ensures a theoretical score as close as possible to reality.