Supervised use cases¶
The « supervised » usecases include tabular or images use cases:
- Regression
- Classification
- Multi classification
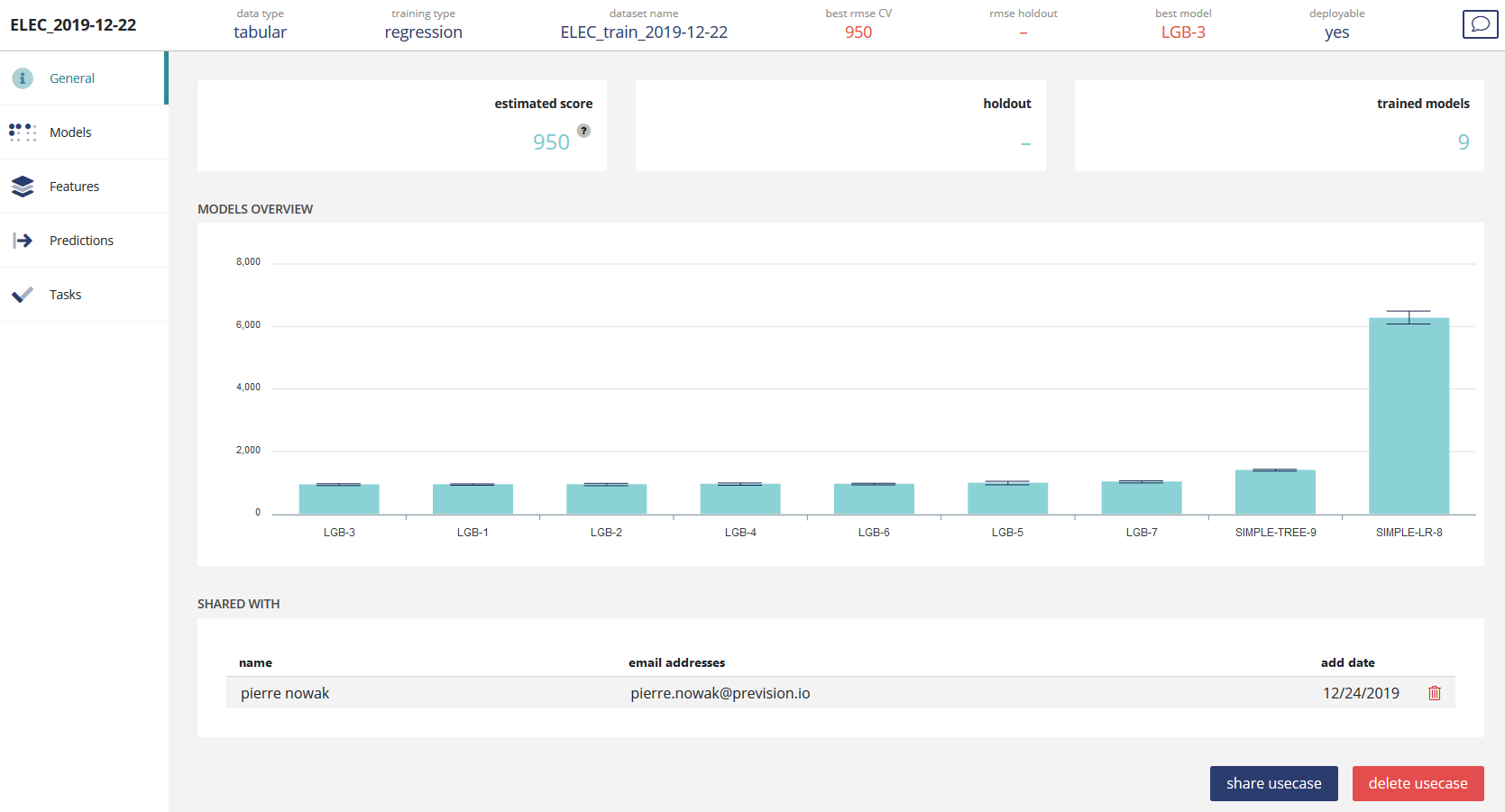
Once a use case of this type is created, whether it is completed or still in process, you can view the performance of the model and data statistics by clicking on the use case name in the dashboard.
You will then be directed to the following screen:
You can also stop or delete the current use cased, depending on his state by clicking on:

or

For each use case, you can navigate through different screens, namely:
- General
- Models
- Features
- Predictions
- Tasks
Note that it is possible to export most of the charts generated by Prevision.io in different formats (PNG, SVG). To do this, simply click on the icon below, located next to the chart in question:

General¶
This screen allows you to view general information about a usecase.
On top of the screen, you will find a sum up of the use case:
- Data type
- Training type
- Name
- Best CV score
- Hold out score (if hold out is provided at start)
- Best model technology
- If the model can be deployed (ready to be put in the Store)
- Number of trained models

While the usecase is running, you can monitor finished, current and upcoming tasks in the execution graph :
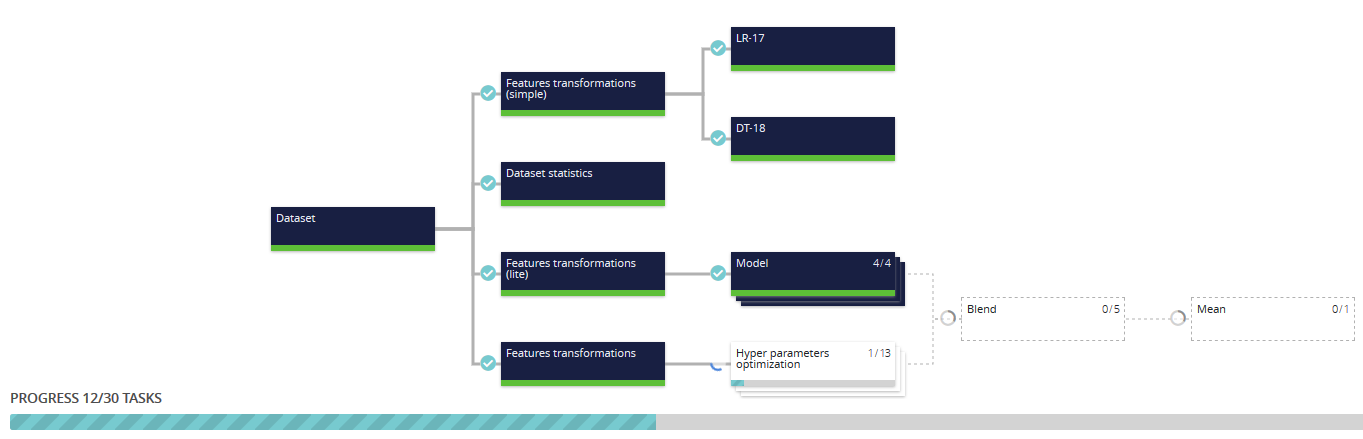
Tasks can be in any one of five states :
- Pending

- Running

- Done

- Failed

- Partially failed

If you want to remind you what type of experiment you have done, you can add a description to your use case by clicking the following button

In any case, as soon as a model is available, a learning plot will be displayed. It represents the evolution of the metric according to the number of models. This plot is either sorted decreasing or increasing depending of the metric. However, best model will be always first (ie on top left) Marks around bars represents a confidence interval of the performance estimator.
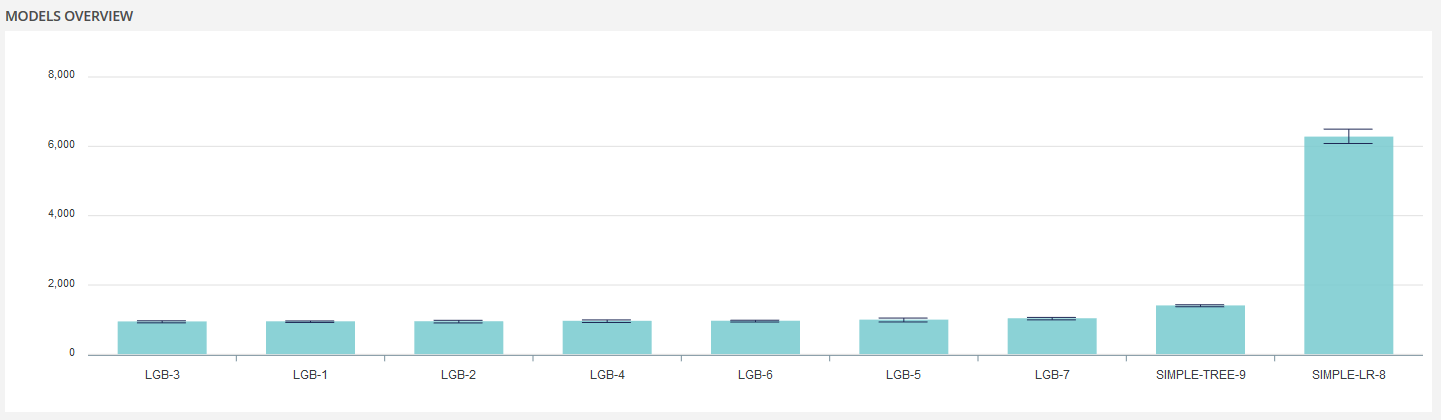
Each bar correspond to one model. Its technology will be written followed by an integer. Example : LGB-3 is a LightGBM type model, that was queued in the 3rd position.
Clicking on a given model will redirect you to the model analysis of the selected one.
Models¶
The model tab will display more information about models linked to the current usecase:
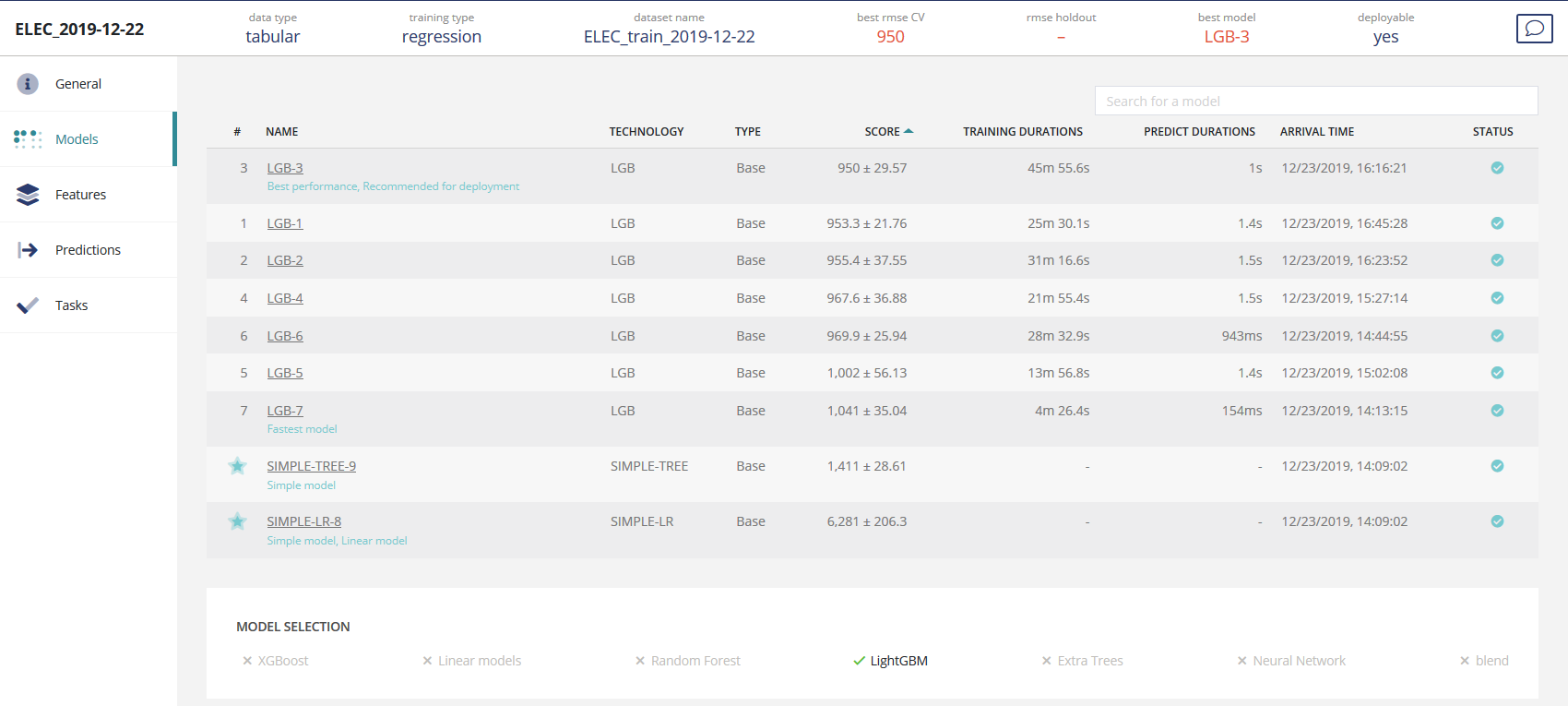
You’ll find a table of every planned and/or trained model for a given usecase and information related to them:
- Model number
- Model name
- Model technology
- Model type (among « base » for standard models, « blend » for a mix of standard models, « mean » for a mean of blends)
- Score (CV estimation +- standard deviation of CV score)
- Training durations (training time of the model)
- Predict durations (estimation of a unit prediction. /!time isn’t linear with the number of predictions)
- Arrival time (time where the model has finished training)
- Status
It should be noted that some of the algorithms (sometimes the same) have badges, namely:
Best performance: The one with the best predictive performanceRecommended for deployment: The model with the best predictive performance that is not a blendFastest model: The one that predicts with the lowest response timeSimple model: A simple model that is visuaisable and can be exported inSQL,PythonorR. Only Linear and Decition trees models can be tagged
Underneath, a table will list what kind of models you have selected during the usecase definition. Here, only LightGBM models have been selected by the user.
Clicking on a model will give you technical information about him and also performance analysis
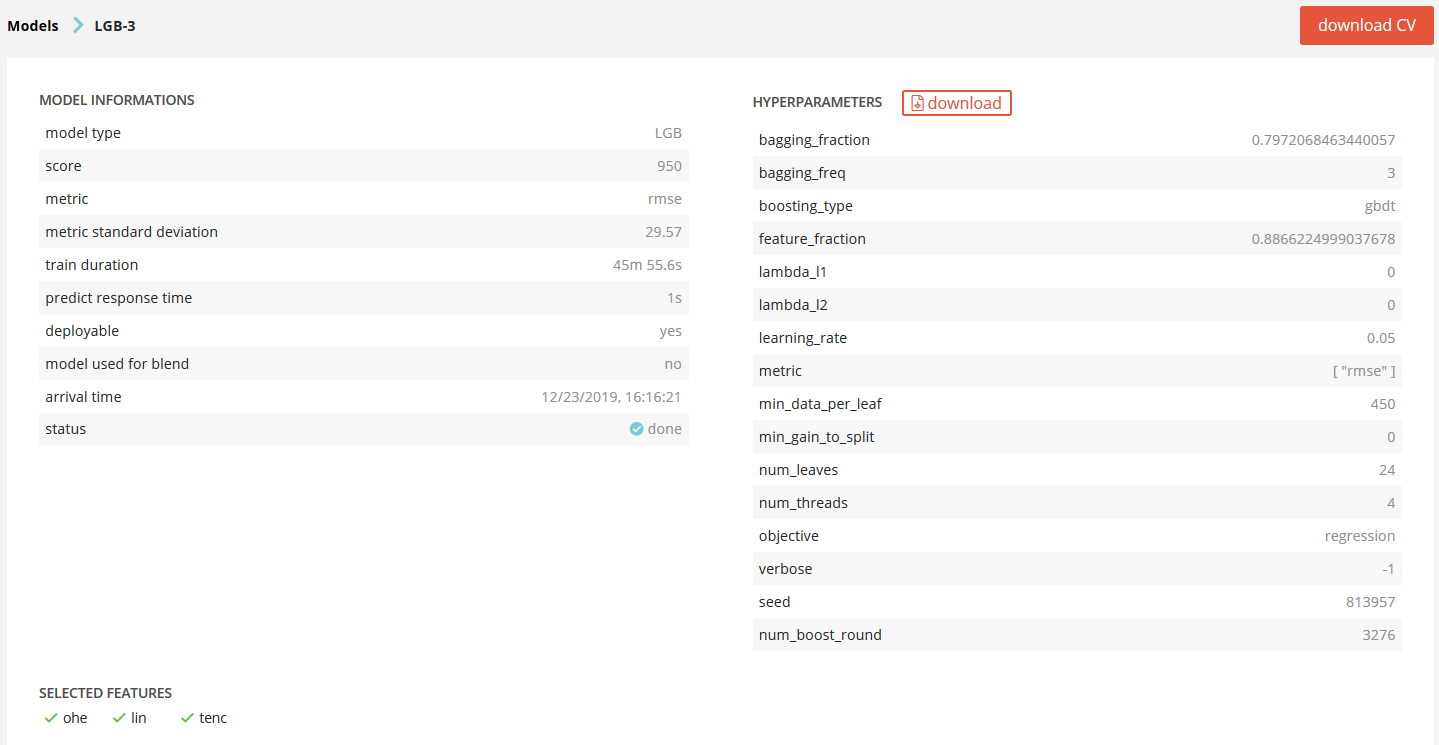
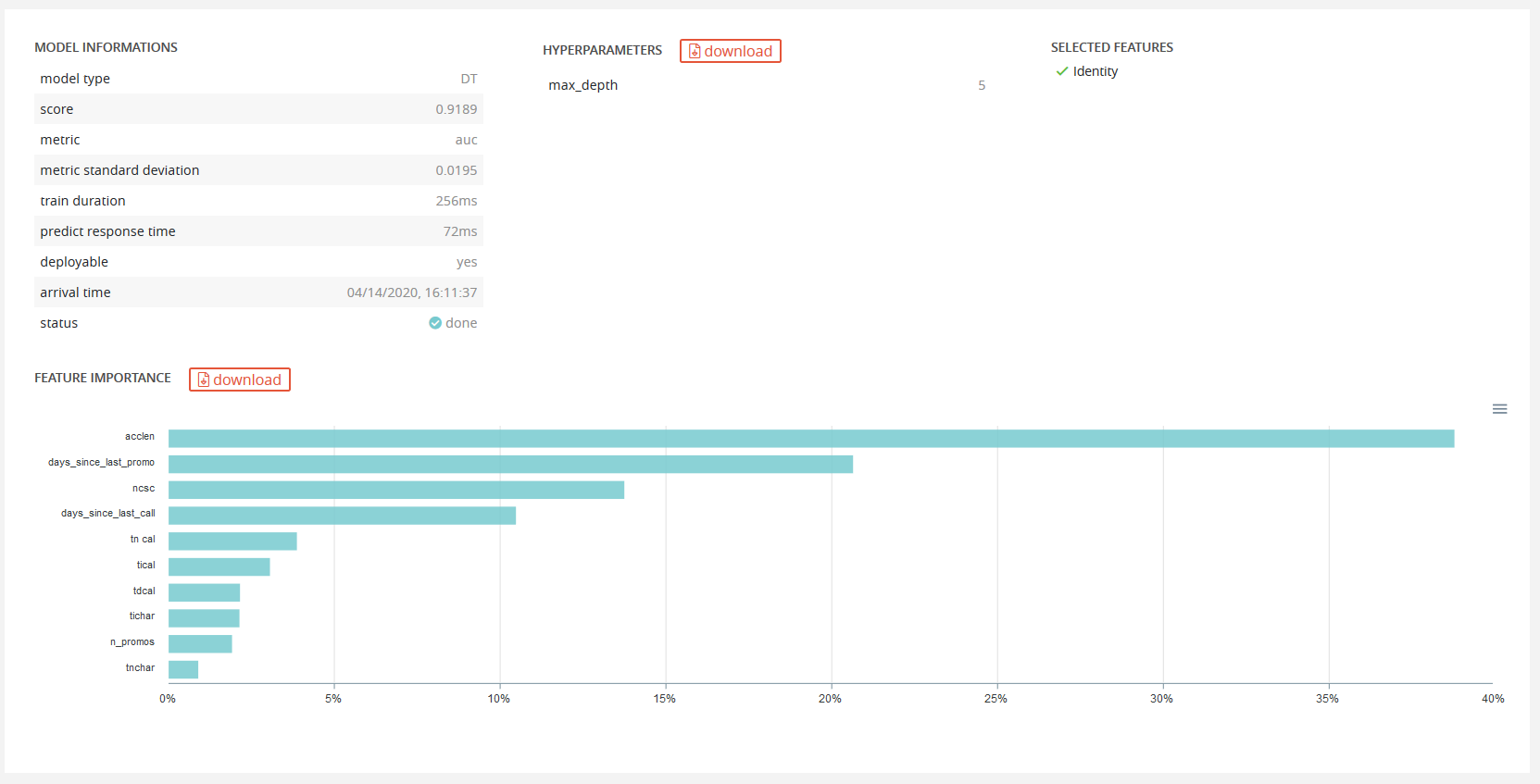
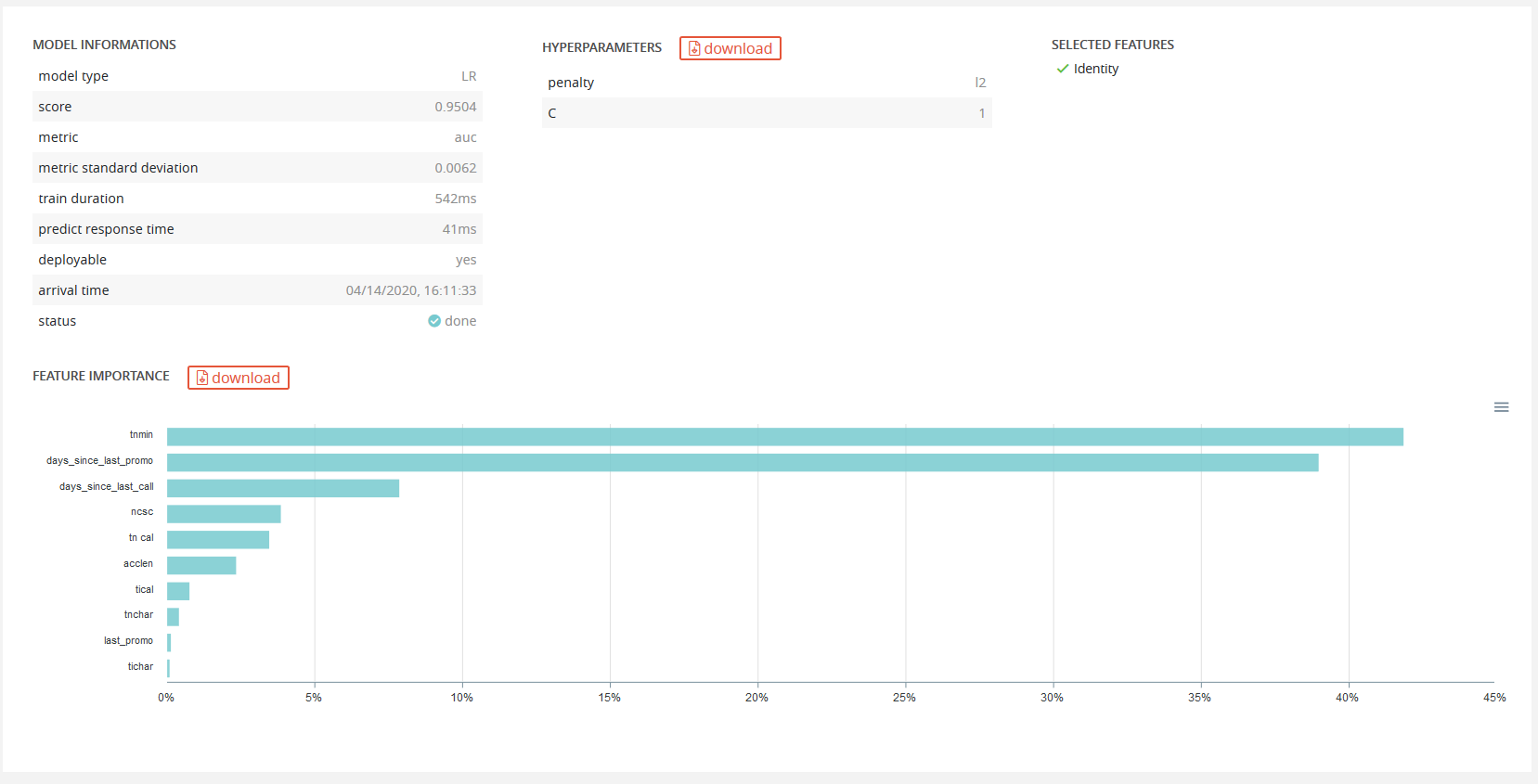
Here we can see more model information, hyper-parameters of the given model and features type retained for the training.
Features types are defined as follow:
- lin: linear features
- ohe: categorical features processed by « one hot encoding »
- freq: categorical features processed by « frequency encoding »
- tenc: categorical features processed by « target encoding »
- ee: categorical features processed by « entity embedding »
- text: text features
- poly: polynomial features
- pca: pca
- kmeans: kmeans clustering done on linear features
It is possible to download hyper-parameters as a JSON and also to download the cross-validation file of the full training set by clicking the top right button.
Feature importance of the selected model will also be displayed:
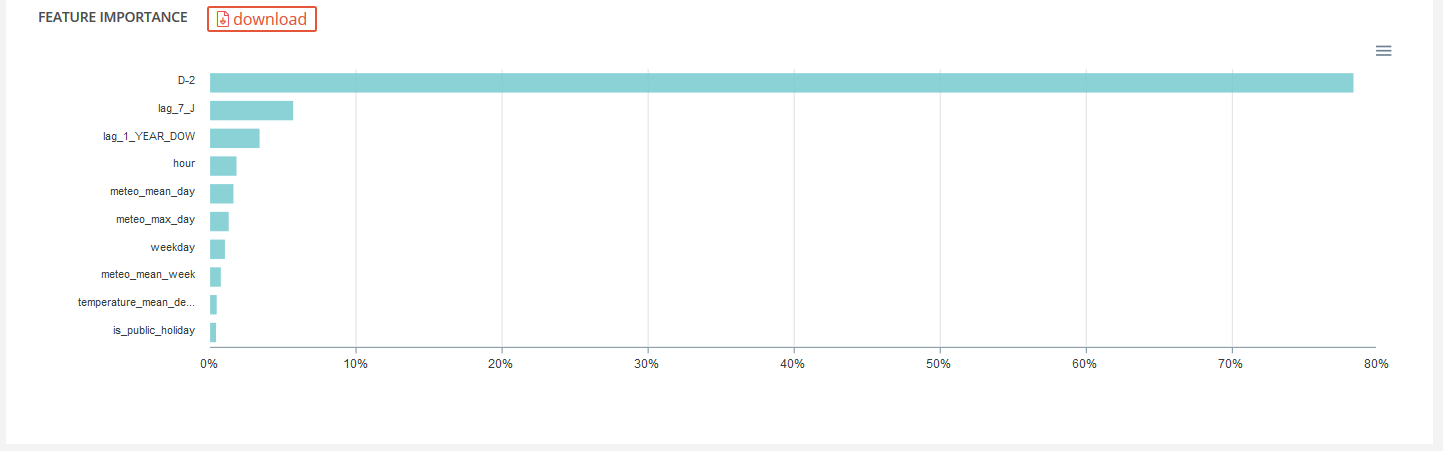
Finally, some performance analysis of models are available. They will differ depending of the usecase type
Regression models¶
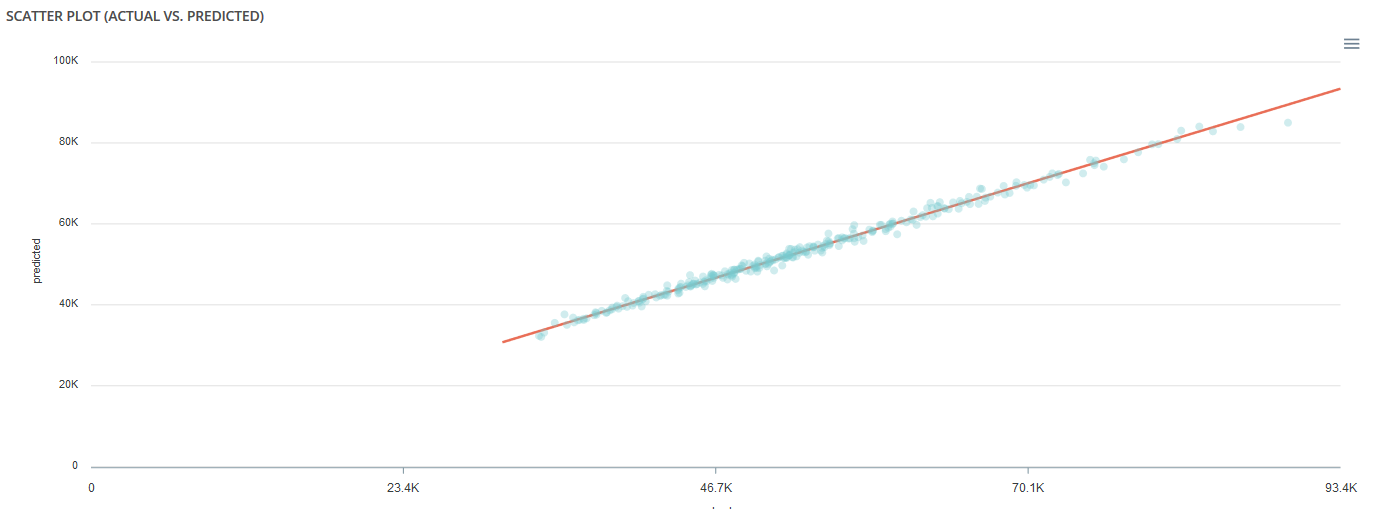
Scatter plot¶
This graph illustrates the actual values versus the values predicted by the model. A powerful model gathers the point cloud around the orange line.
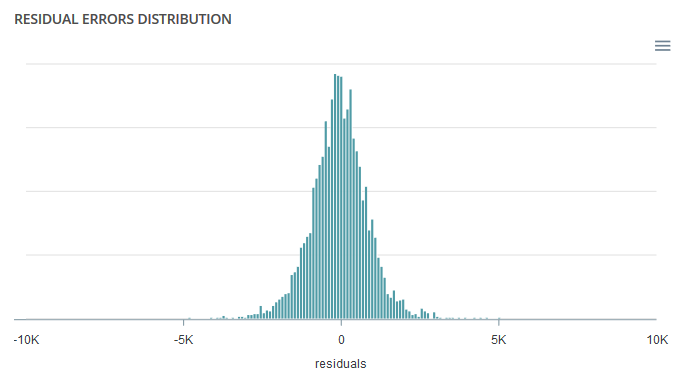
Residuals¶
This graph illustrates the dispersion of errors, i.e. residuals. A successful model displays centered and symmetric residues around 0.
Score table¶
Among the displayed metrics, we have:
- The mean square error (MSE)
- The root of the mean square error (RMSE)
- The mean absolute error (MAE)
- The coefficient of determination (R2)
- The mean absolute percentage error (MAPE)

Classification models¶
Slider¶
For a binary classification, some graphs and scores may vary according to a probability threshold in relation to which the upper values are considered positive and the lower values negative. This is the case for:
- The scores
- The confusion matrix
- The cost matrix
Thus, you can define the optimal threshold according to your preferences. By default, the threshold corresponds to the one that minimizes the F1-Score. Should you change the position of the threshold, you can click on the « back to optimal » link to position the cursor back to the probability that maximizes the F1-Score.

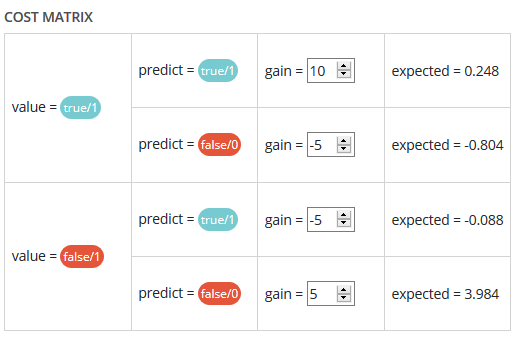
Cost matrix¶
Provided that you can quantify the gains or losses associated with true positives, false positives, false negatives, and true negatives, the cost matrix works as an estimator of the average gain for a prediction made by your classifier. In the case explained below, each prediction yields an average of €2.83.
The matrix is initiated with default values that can be freely modified.
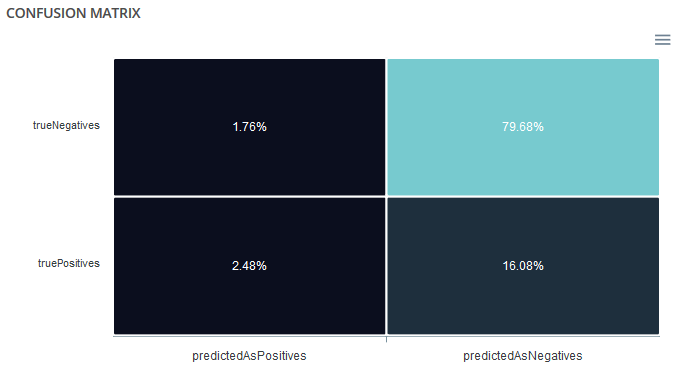
Confusion matrix¶
The confusion matrix helps to understand the distribution of true positives, false positives, true negatives and false negatives according to the probability threshold. The boxes in the matrix are darker for large quantities and lighter for small quantities.
Ideally, most classified individuals should be located on the diagonal of your matrix.
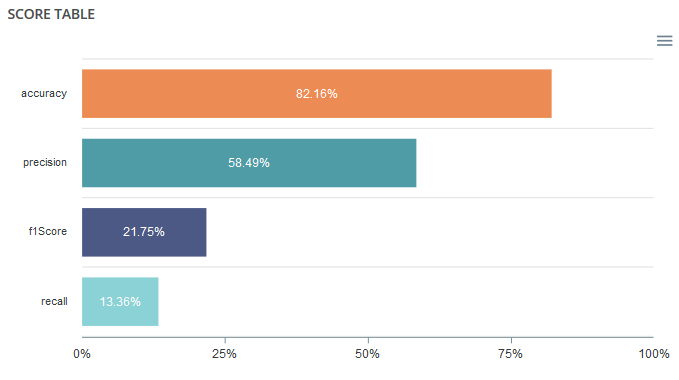
Score table¶
Among the displayed metrics, we have:
- Accuracy: The sum of true positives and true negatives divided by the number of individuals
- F1-Score: Harmonic mean of the precision and the recall
- Precision: True positives divided by the sum of positives
- Recall: True positives divided by the sum of true positives and false negatives
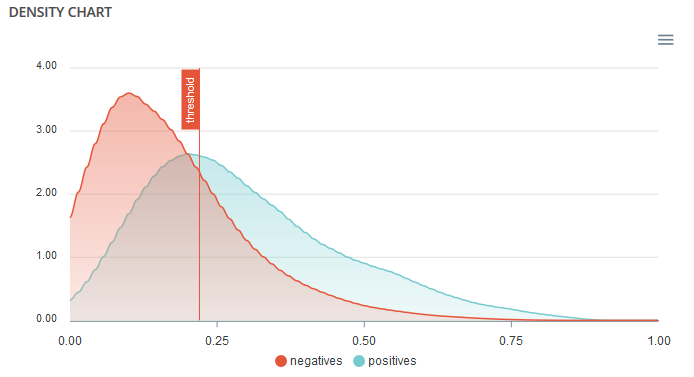
Density chart¶
The density graph allows you to understand the density of positives and negatives among the predictions. The more efficient your classifier is, the more the 2 density curves are disjointed and centered around 0 and 1.
Gain chart¶
The gain graph allows you to quickly visualize the optimal threshold to select in order to maximise the gain as defined in the cost matrix.
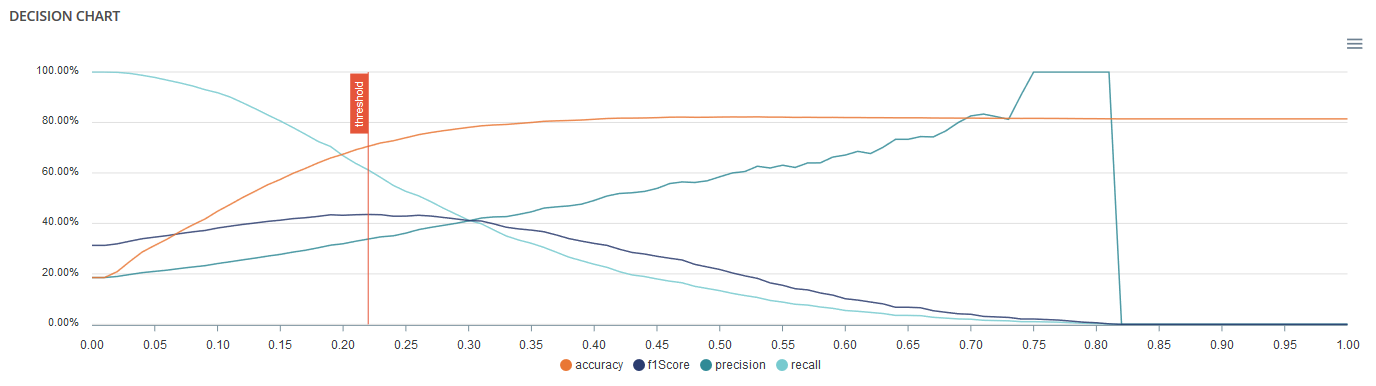
Decision chart¶
The decision graph allows you to quickly visualize all the proposed metrics, regardless of the probability threshold. Thus, one can visualize at what point the maximum of each metric is reached, making it possible for one to choose its selection threshold.
It should be noted that the discontinuous line curve illustrates the expected gain by prediction. It is therefore totally linked to the cost matrix and will be updated if you change the gain of one of the 4 possible cases in the matrix.
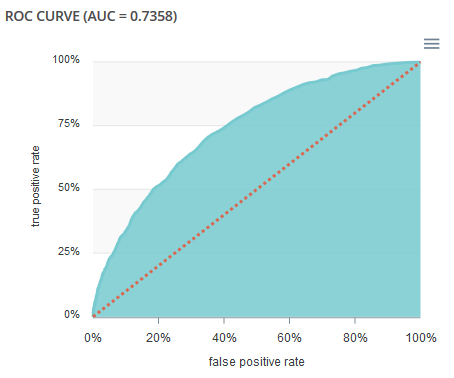
ROC curve¶
The ROC curve illustrates the overall performance of the classifier (more info: https://en.wikipedia.org/wiki/Receiver_operating_characteristic). The more the curve appears linear, the closer the quality of the classifier is to a random process. The more the curve tends towards the upper left side, the closer the quality of your classifier is to perfection.
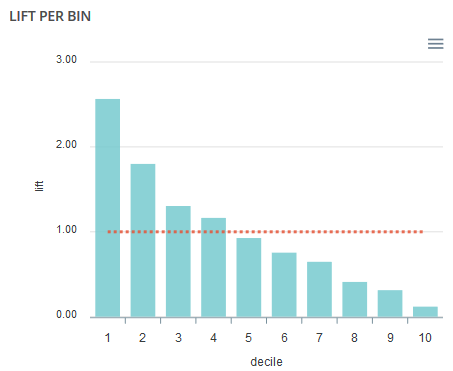
Lift per bin¶
The predictions are sorted in descending order and the lift of each decile (bin) is indicated in the graph. Example: A lift of 4 means that there are 4 times more positives in the considered decile than on average in the population.
The orange horizontal line shows a lift at 1.
Cumulated lift¶
The objective of this curve is to measure what proportion of the positives can be achieved by targeting only a subsample of the population. It therefore illustrates the proportion of positives according to the proportion of the selected sub-population.
A diagonal line (orange) illustrates a random pattern (= x % of the positives are obtained by randomly drawing x % of the population). A segmented line (blue) illustrates a perfect model (= 100% of positives are obtained by targeting only the population’s positive rate).
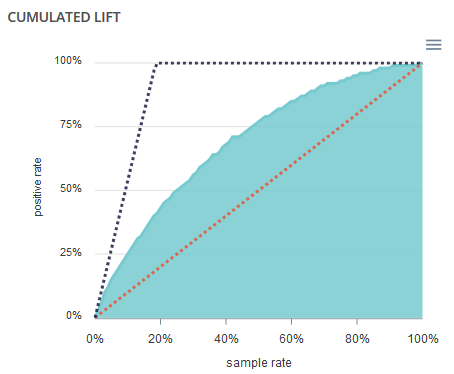
Multiclassification models¶
Score table¶
Among the displayed metrics, we have displayed the macro averaged:
- Accuracy
- Precision
- Recall
- F1-Score
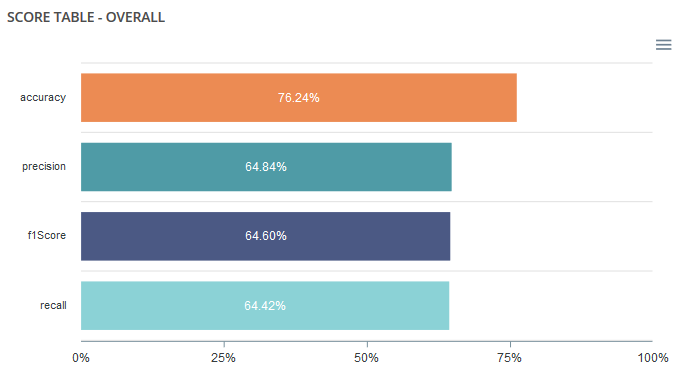
Confusion matrix¶
The confusion matrix makes it possible to understand the distribution of predicted values compared to actual values between classes. The boxes in the matrix are darker for large quantities and lighter for small quantities.
Ideally, most classified individuals should be located on the diagonal of your matrix.
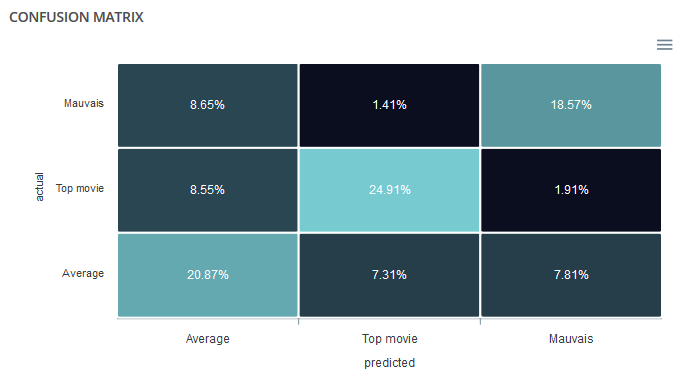
ROC curve & per class analysis¶
The ROC curve illustrates the overall performance of the classifier (more info: https://en.wikipedia.org/wiki/Receiver_operating_characteristic). The more the curve appears linear, the closer the quality of the classifier is to a random process. The more the curve tends towards the upper left side, the closer the quality of your classifier is to perfection.
Within the framework of multiclass classification, there are as many curves as there are classes. They are calculated in « one- versus-all ».
Also, for each class, you’ll have detailed metric of it on the right part of the screen:
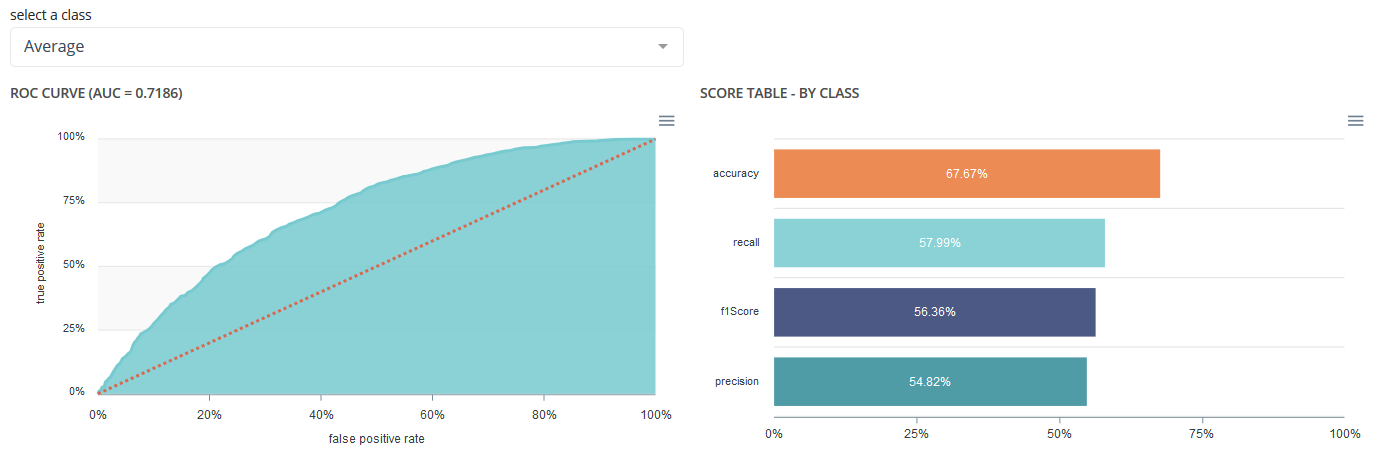
Simple models¶
For every use case, 2 simples models will be trained. One will be tree based the other one will be linear (or logistic, depending of the corresponding TRAINING TYPE)
Please keep in mind that, because of the nature of simplified models, their predictive power might be lower than more complex one but are easier to understand and to communication to business users.
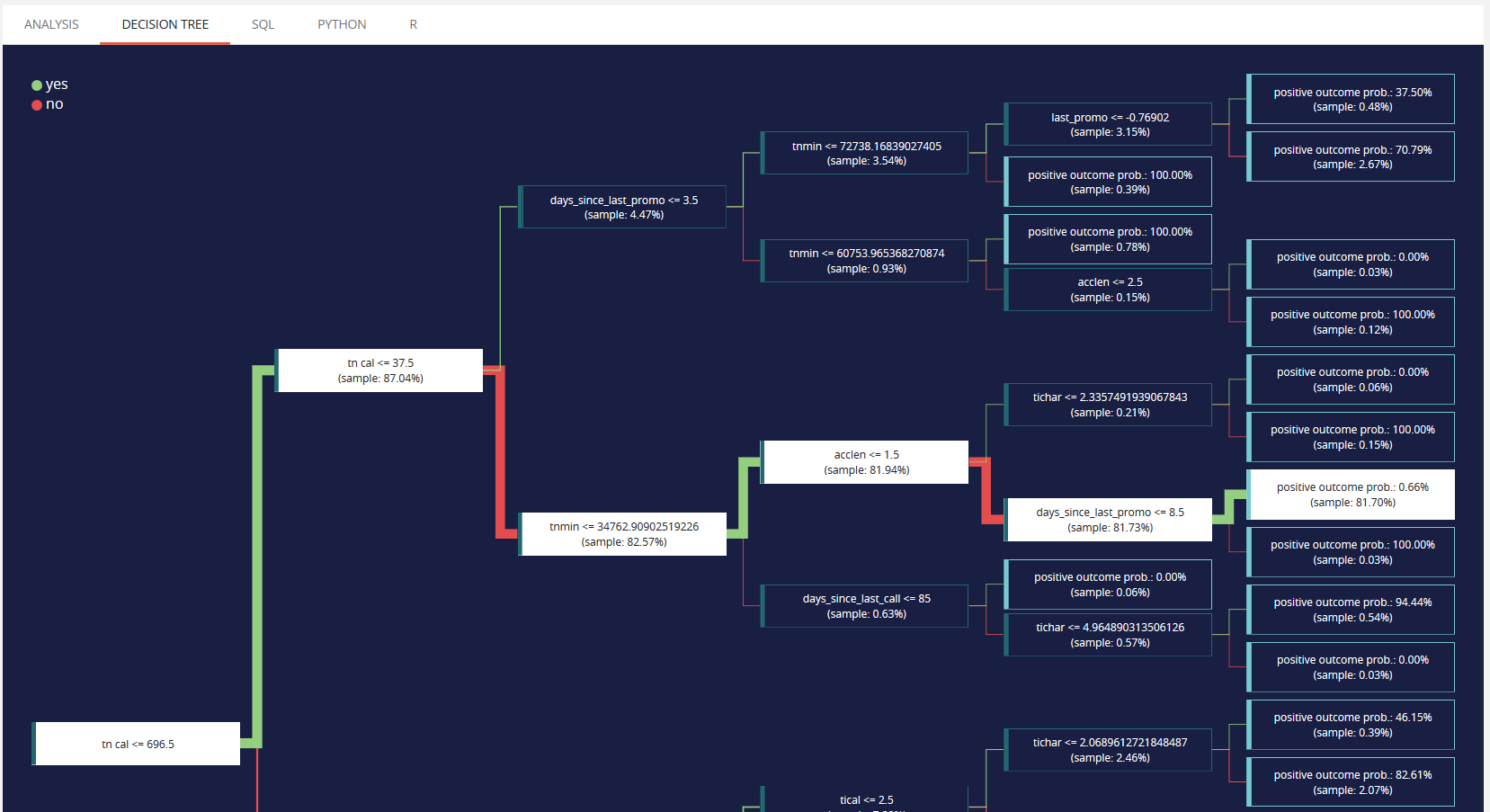
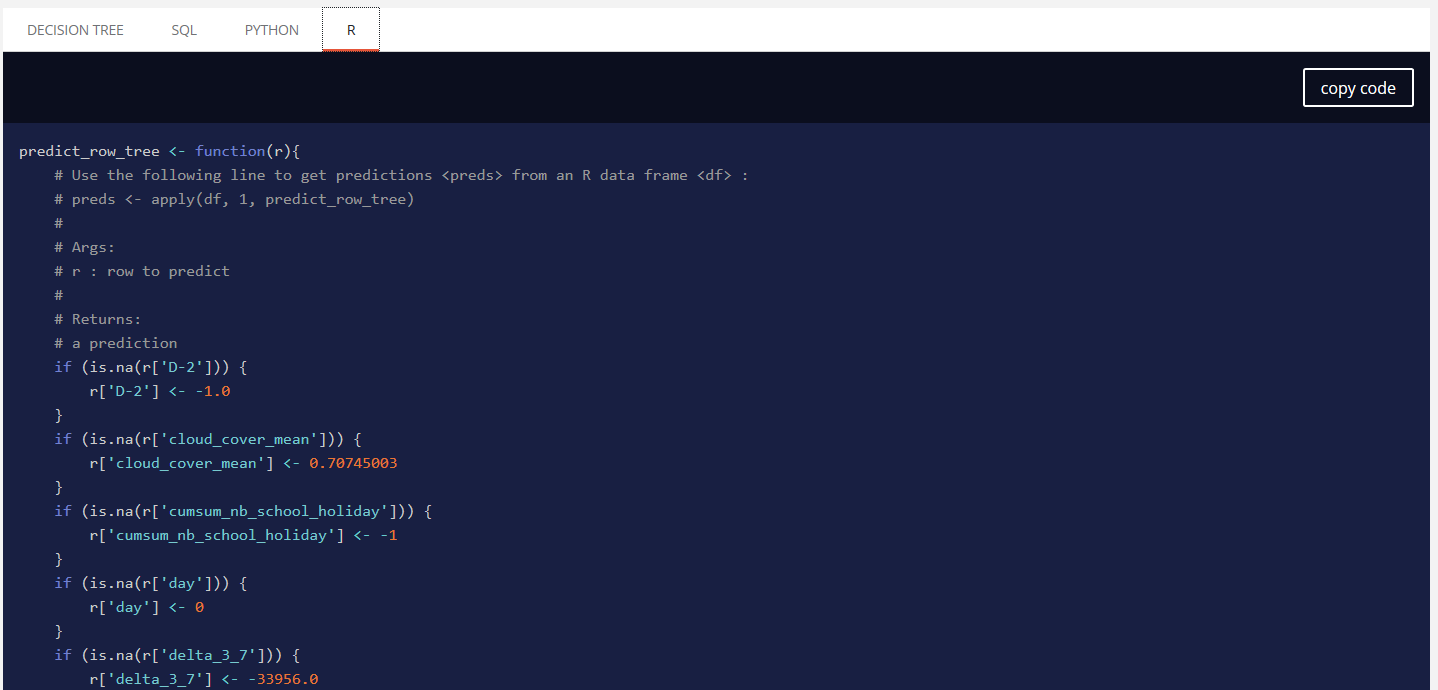
Decision tree¶
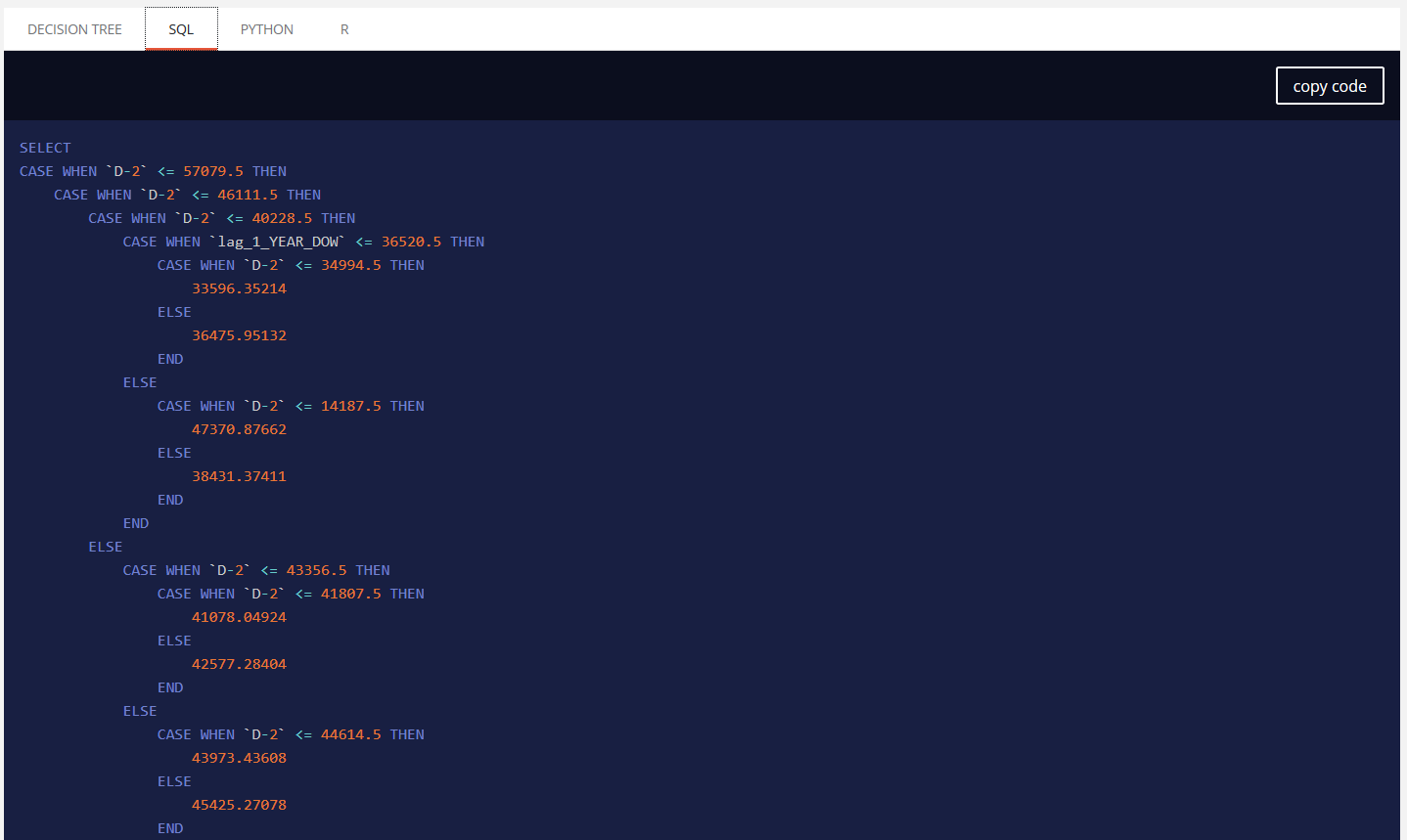
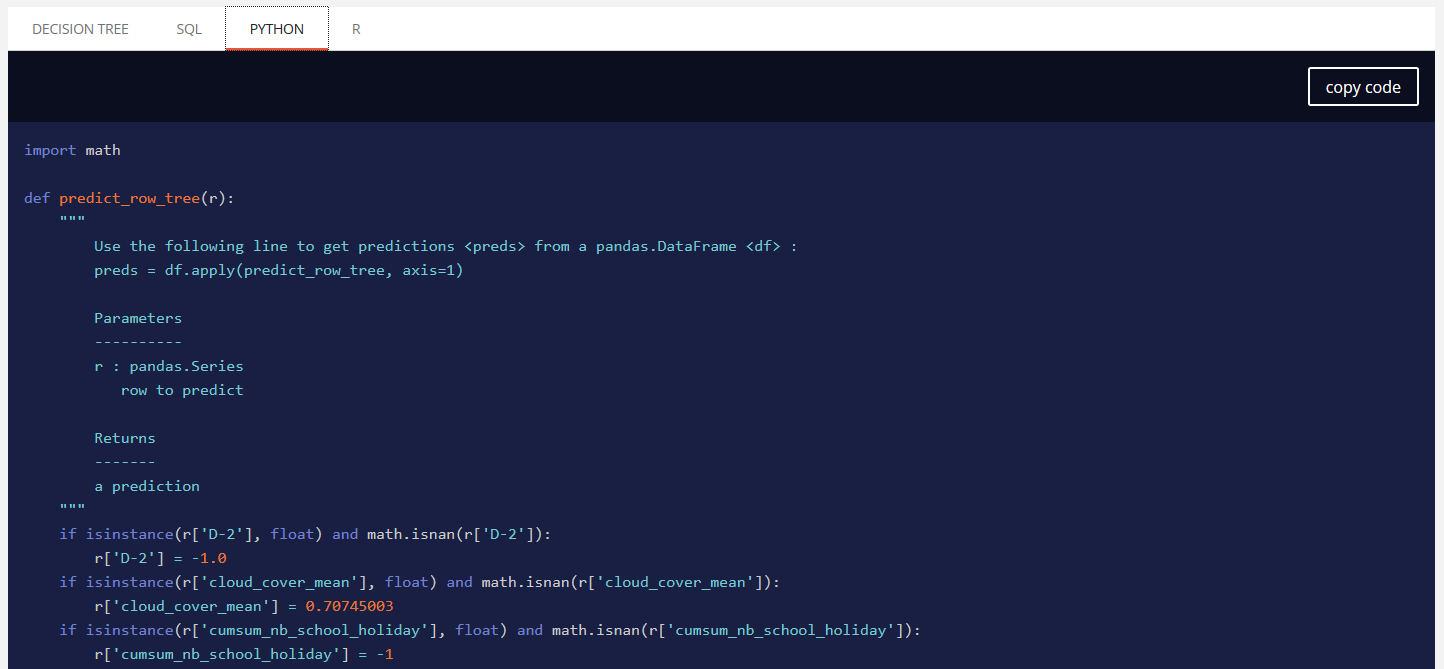
A simplified decision tree is available. It will have the same level of information of other models, can be fully displayed and is also exportable as SQL, PYTHON and R directly with code generated
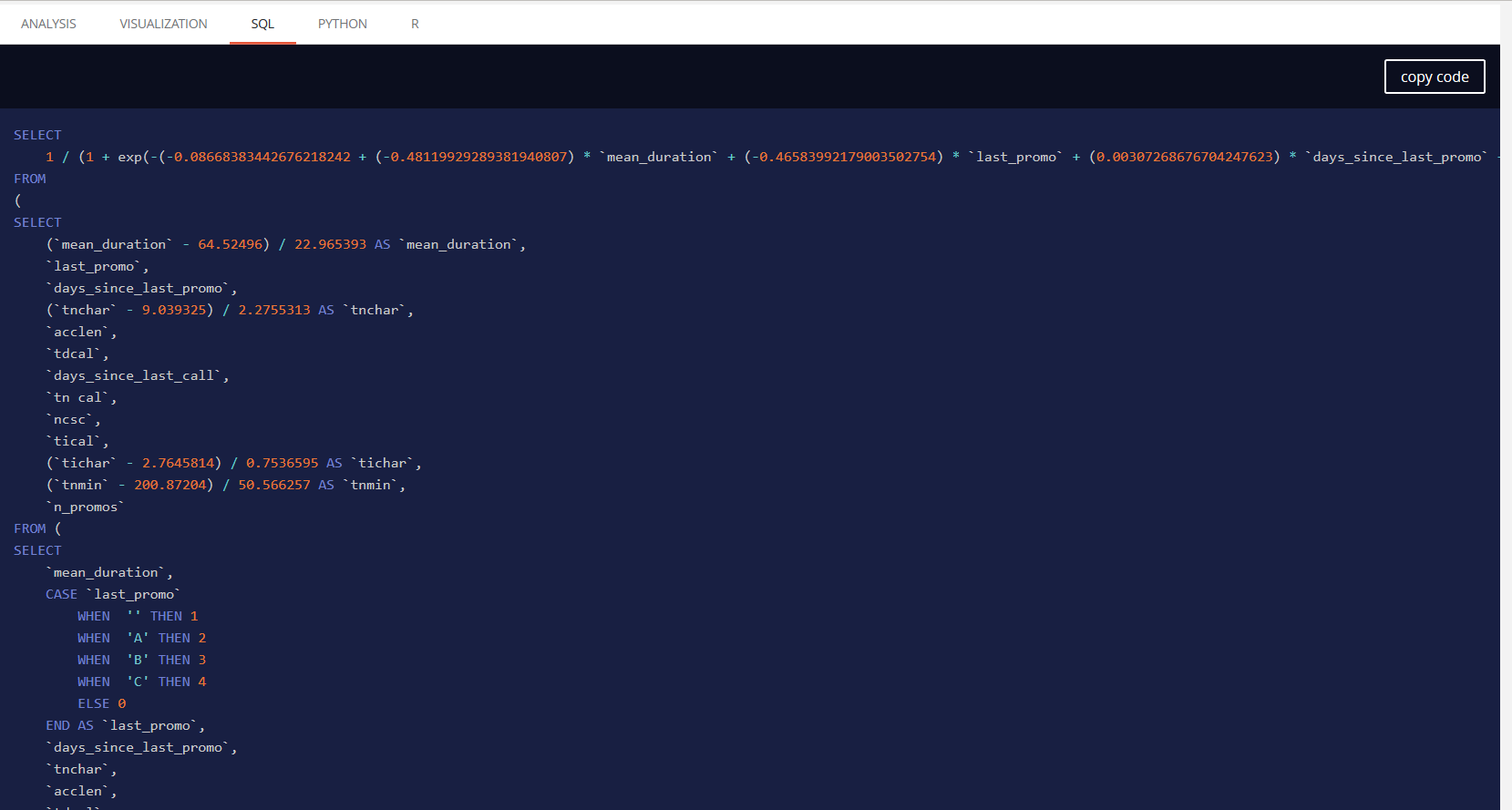
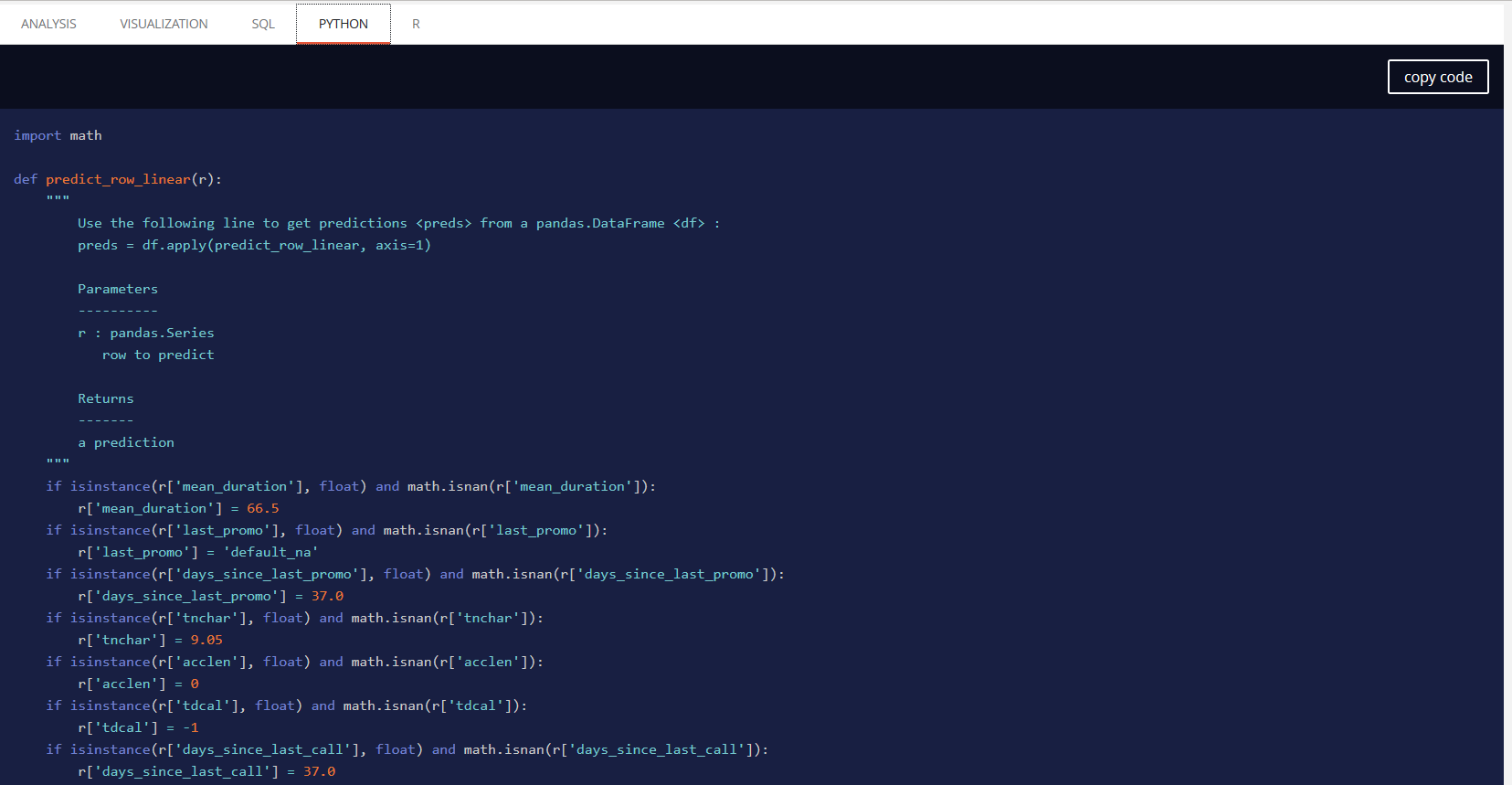
Linear model¶
A simplified linear (or logistic when doing a classification) regression is available. It will have the same level of information of other models, can be fully displayed and is also exportable as SQL, PYTHON and R directly with code generated

Features¶
Detailed information about features linked to a usecase are available in the screen:
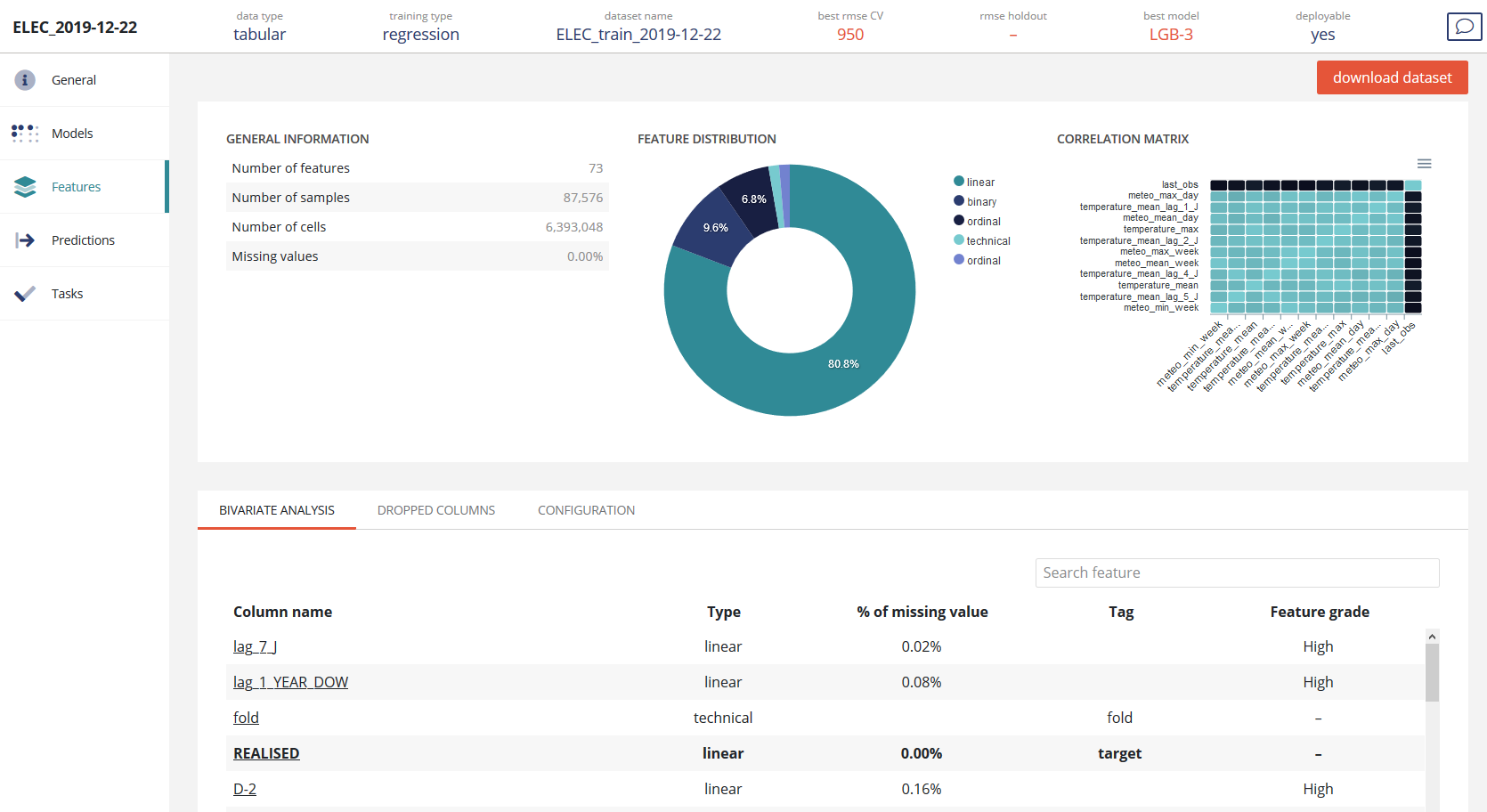
You’ll find the same information that in the dataset page, with some additional statistics calculated on this specific usecase :
- Feature grade: in one word if the feature is globally important for the use case
- Dropped column for the usecase
- Configuration of feature engineering to be done on the usecase
Clicking on a given feature will give you some detailed analytics on it:
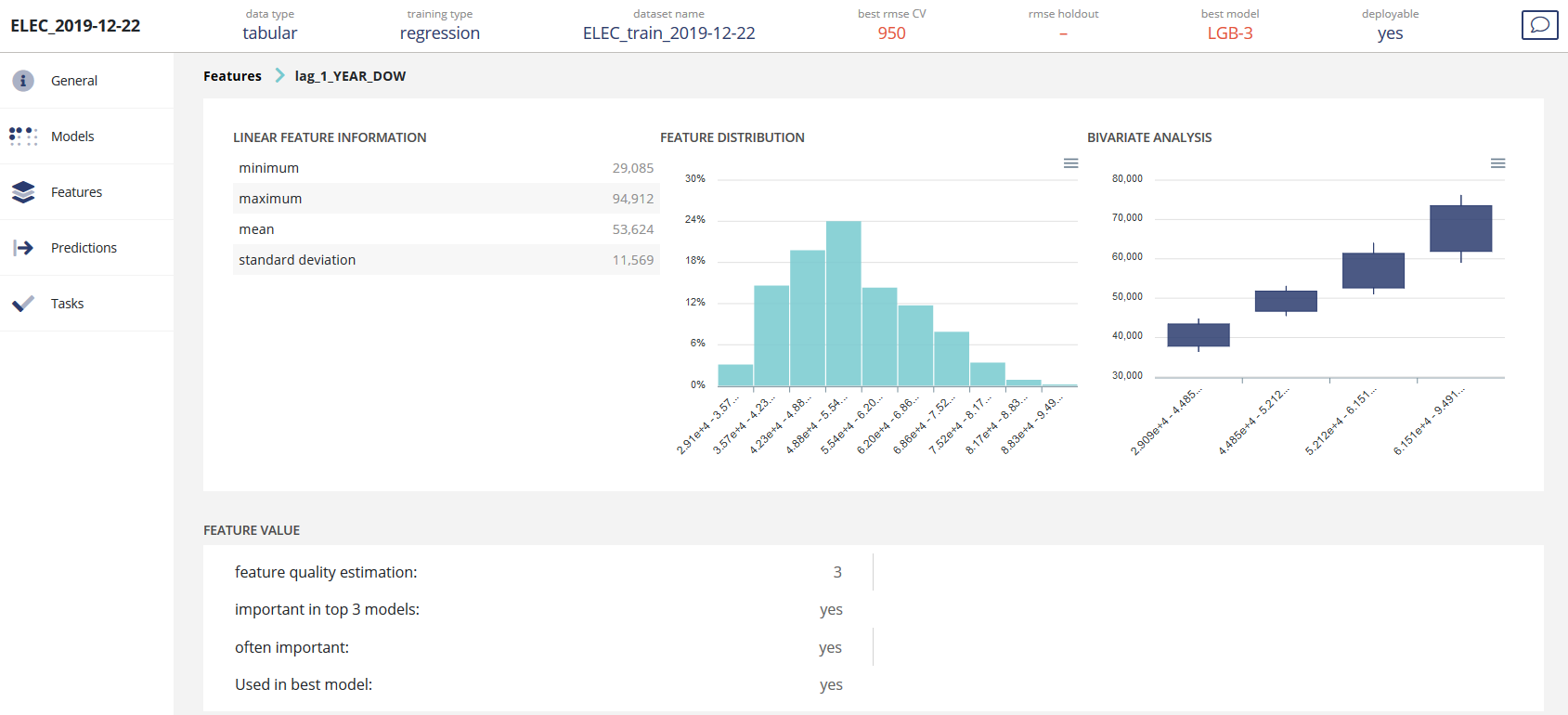
You will find a summary of the feature, its distribution and its bivariate distribution conditioned to the TARGET
Predictions¶
All predictions linked to a usecase are available in the screen:
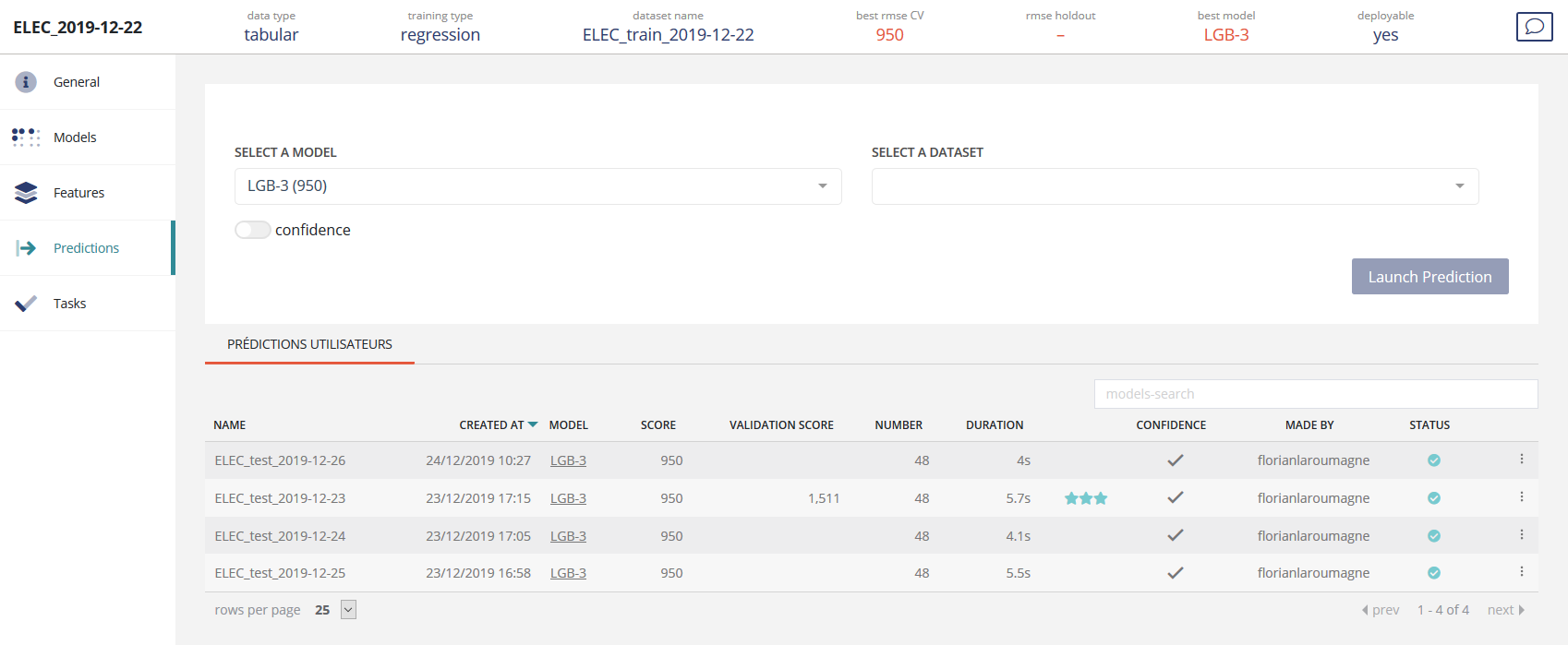
In order to create a new prediction, you need to select a model (the best one is selected by default) and to select a dataset you want to predict on and clicking on the « Launch Prediction » button.
It is imperative that it has the same structure as the learning set, with the exception of the following technical columns: [TARGET, WEIGHT, FOLD], which are generaly not present in the data set to be predicted.
If the file sent contained a TARGET, which may be the case when benchmarking, the platform will automatically calculate the score on the test set and display it next to the estimated cross-validation score.
Note that when columns are missing in the test set, the platform will ask you if you really want to perform the prediction. If you confirm your choice, the relevant columns will be imputed with missing data over the entire dataset. Note that this can influence the performance of the prediction.
All predictions requested by the user will be listed in a table containing:
Name of the dataset to predict on
Creation date of the prediction
Selected model
Score estimated by the CV process
Validation score: only available if the TARGET is given in the dataset to be predicted on
Number of individuals (rows) predicted
Duration of the prediction
Has confidence been enabled?
Who requester the prediction
Status of the prediction
Action link:
- Explanation
- Prediction file download
- Remove the prediction
Please note that if a hold out dataset has been provided, a new tab called « hold out prediction » will contains directly prediction of the hold out for each trained model with the same information of user’s predictions.
In addition to providing prediction, Prevision.io offers the ability to quantify the level of certainty around this prediction. Thus, we can know if the algorithms are confident or if they have doubts about the predicted value.
To access this additional information, you must tick the « confidence » slider when sending a dataset for prediction.
Note that this feature slightly increases the prediction time. We therefore recommend that you use it only when you feel it is necessary.
In the case of a regression, you will have 10 new columns in the dataset. Indeed, in addition to the traditional couple (ID, TARGET) you will also have the variables:
- TARGET_quantile=1
- TARGET_quantile=5
- TARGET_quantile=10
- TARGET_quantile=25
- TARGET_quantile=50
- TARGET_quantile=75
- TARGET_quantile=90
- TARGET_quantile=95
- TARGET_quantile=99
These features correspond to the quantiles at 1%, 5%, 10% … That is to say, we estimate that there is an X% chance that the prediction is below the quantile X.
In the case of a classification or a multiclass classification you will also obtain 2 new variables: « confidence » and « credibility ».
Confidence is an indicator of certainty that corresponds to a possible conflict between the majority class and the other classes. Thus, the higher the confidence, the more confident we are that the class with the highest probability is the right one. This makes sense in multiclass classifications. For example:
| Class_1 | Class_2 | Class_3 |
|---|---|---|
| 0.9 | 0.05 | 0.05 |
| 0.5 | 0.45 | 0.05 |
In a case like this, « Class_1 » always holds the majority. In the first example, the algorithm clearly favors the majority class when distributing the probabilities: it will therefore have high confidence. Conversely, in the second example there is a likely conflict between « Class_1 » and « Class_2 ». Confidence will therefore be reduced.
Credibility is another indicator of certainty that specifies whether the prediction is based on a similar decision – and therefore close to an example of the training dataset – or whether it does not resemble any known case.
Let us imagine that we have a use case that consists in predicting house prices. Let’s say we want to predict the price of an 80m2 house: in this case, there is nothing out of the ordinary, there are probably houses of 80m2 in the training dataset so the credibility will be high. Now, suppose we want to predict the price of a 700m2 loft.
This type of housing being little or not represented, the algorithm will predict a price (probably very high) but its credibility will be low because this type of housing does not really resemble a typology present in the training dataset.
In addition to certainty indicators, Prevision.io allows users to understand the decision made by algorithms at the level of the statistical individual.
To obtain an explicability report, you must click the « explain » action link on the prediction you want to explain.
Warning: It may take some time to load this screen, especially if the number of individuals to explain is large.
You will then reach the next page:
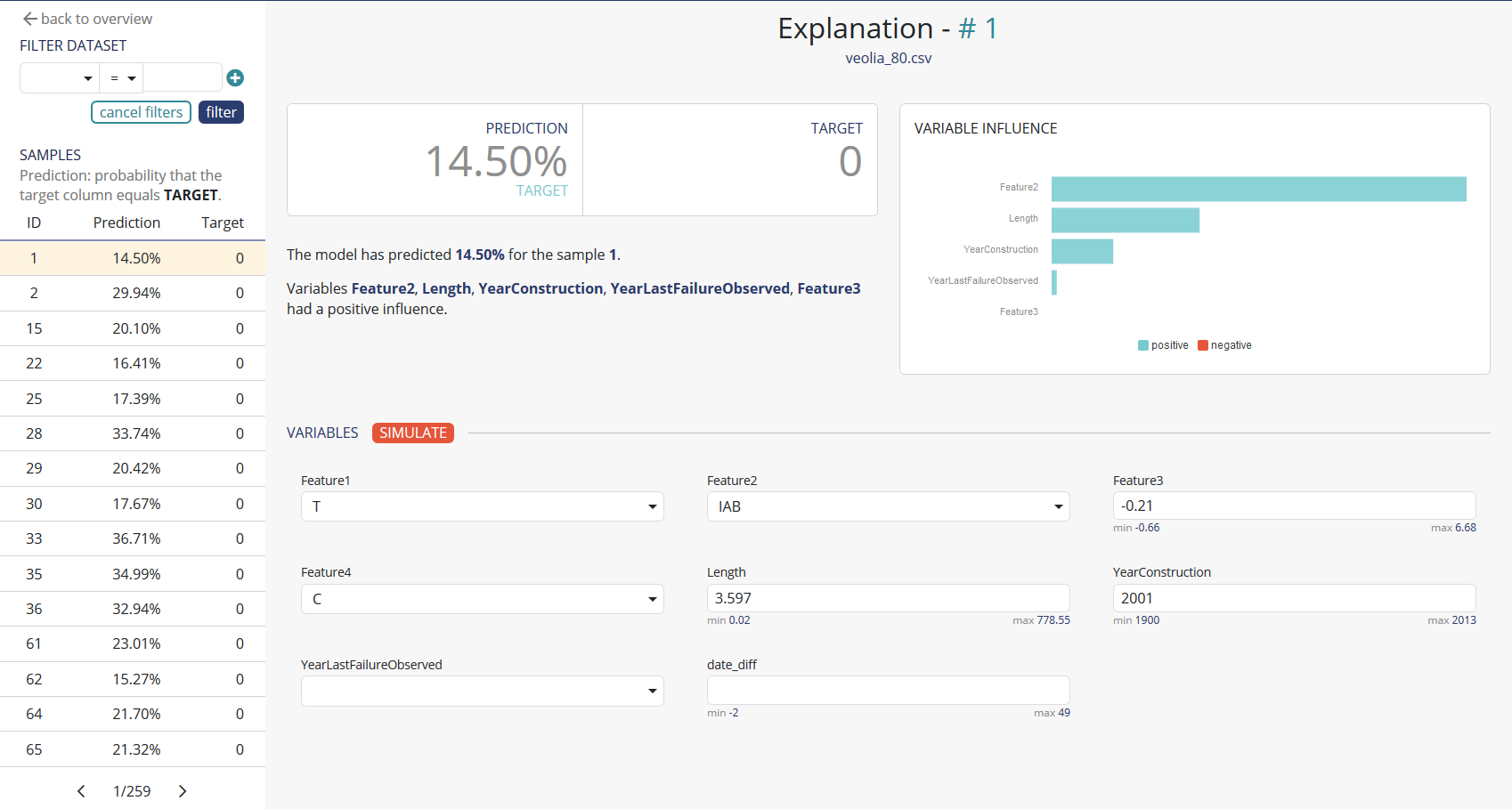
At the top left, you will find an interface that allows you to filter predictions according to the values of their variables. Up to 2 filters (and/or) can be used simultaneously.
Below, you will find a list of the predictions corresponding to the considered perimeter (with all default predictions). Each line of this table is clickable, the information will then be updated directly on the right side of the screen.
Each prediction is explained, the most important features for the prediction considered are explained in a sentence and also in the graph at the top right:
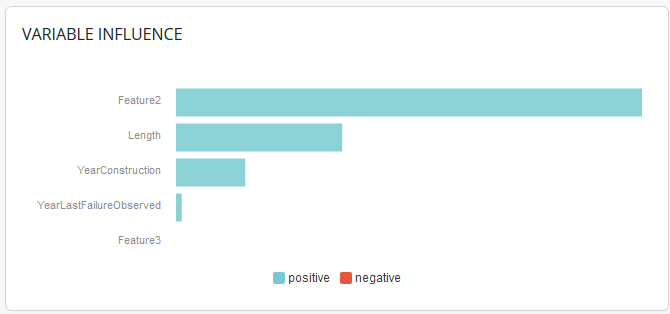
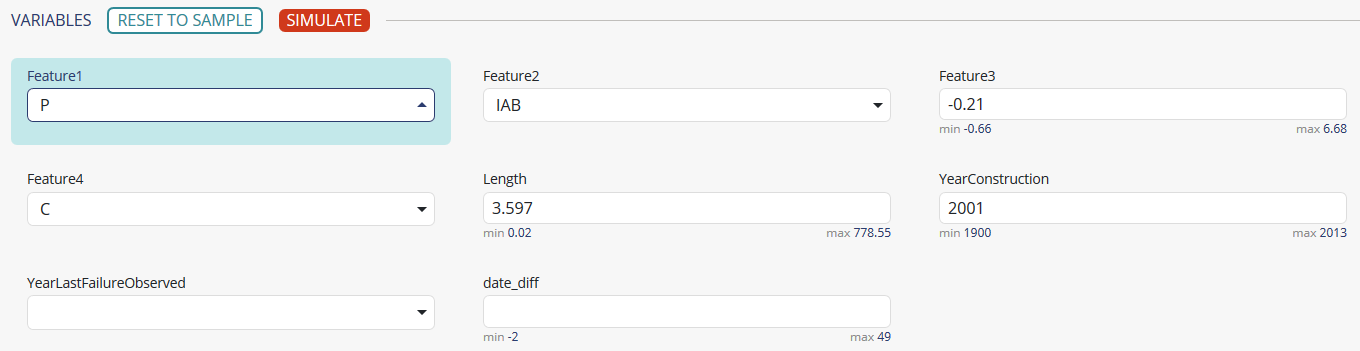
The lower part of the table features all the values of the features of the selected prediction. It is possible to modify them on the go and clicking on the « simulate » button to see a new prediction and explanation:
Tasks¶
Tasks linked to the usecase will be displayed here:
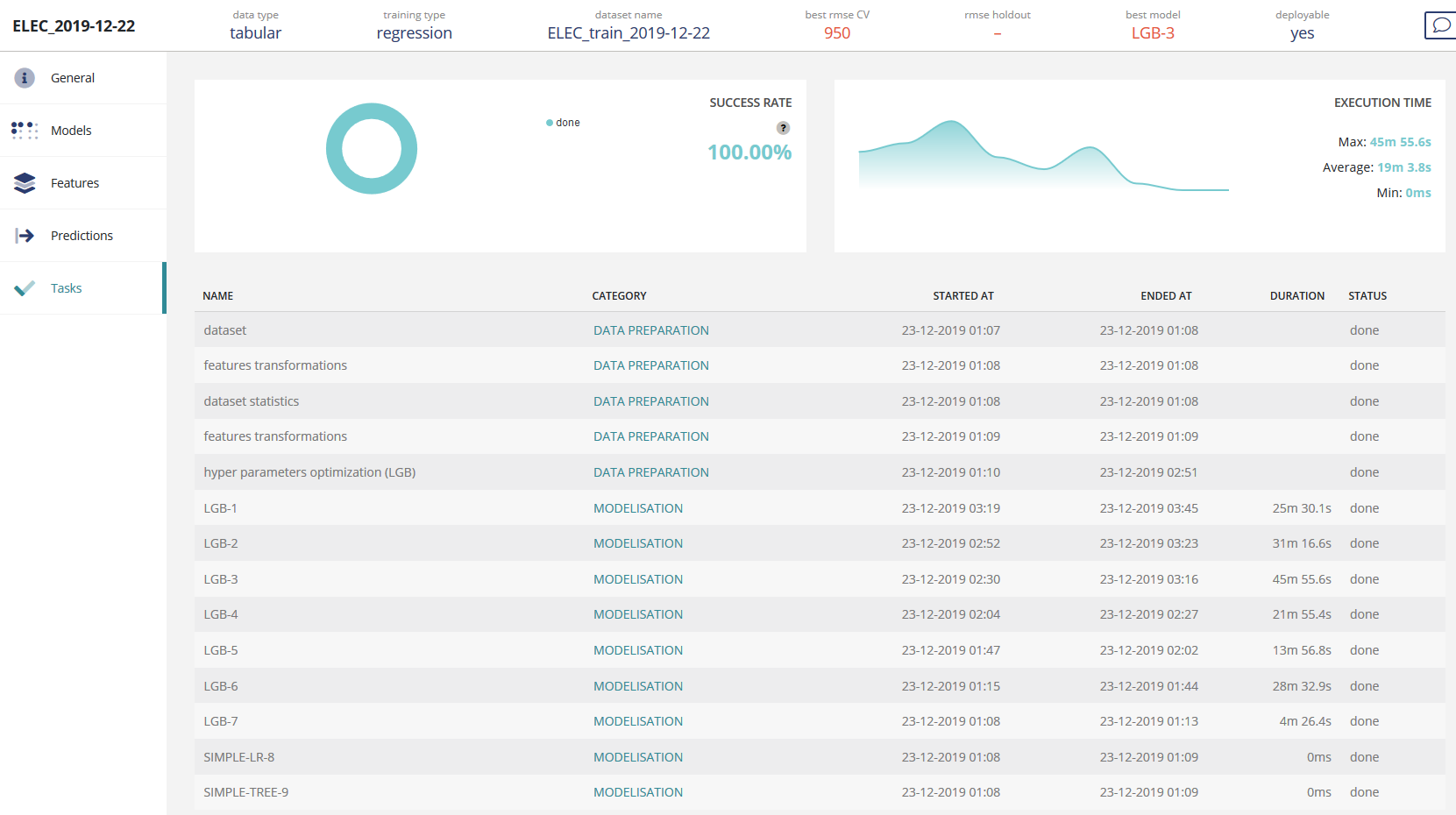
You’ll find:
Success rate of tasks (100% means all finished successfully)
Execution time of tasks, ordered by tasks arrival
A table with more detailed information:
- Task name
- Task category
- Task start date
- Task end date
- Task duration
- Task status