Deployments¶
Deployments are the last step of a Machine Learning Project and are used to
- share model across your organisation
- start monitoring you models
Deployments need experiments with at least one model. You can deploy any model of any version of your experiment.
Once an experiment is deployed…
- you can schedule batch prediction
- you can monitor performance of one main model and one challenger
- external users can use your model for unit prediction from an url
- external application can call your model from a REST API
Deployments are scoped to a project and available from the deployments section on the collapsing sidebar. When entering the deployment section, you will see a list of each of your deployment and two status :
- deployed : are models built and available over API
- running : does API reponses to request
The url column links to a page where human can call the model over a simple form in order to test it.
Create a new Deployments¶
Creating a new deployment is done by clicking on the deploy a new experiment button under the deployments experiments tab.
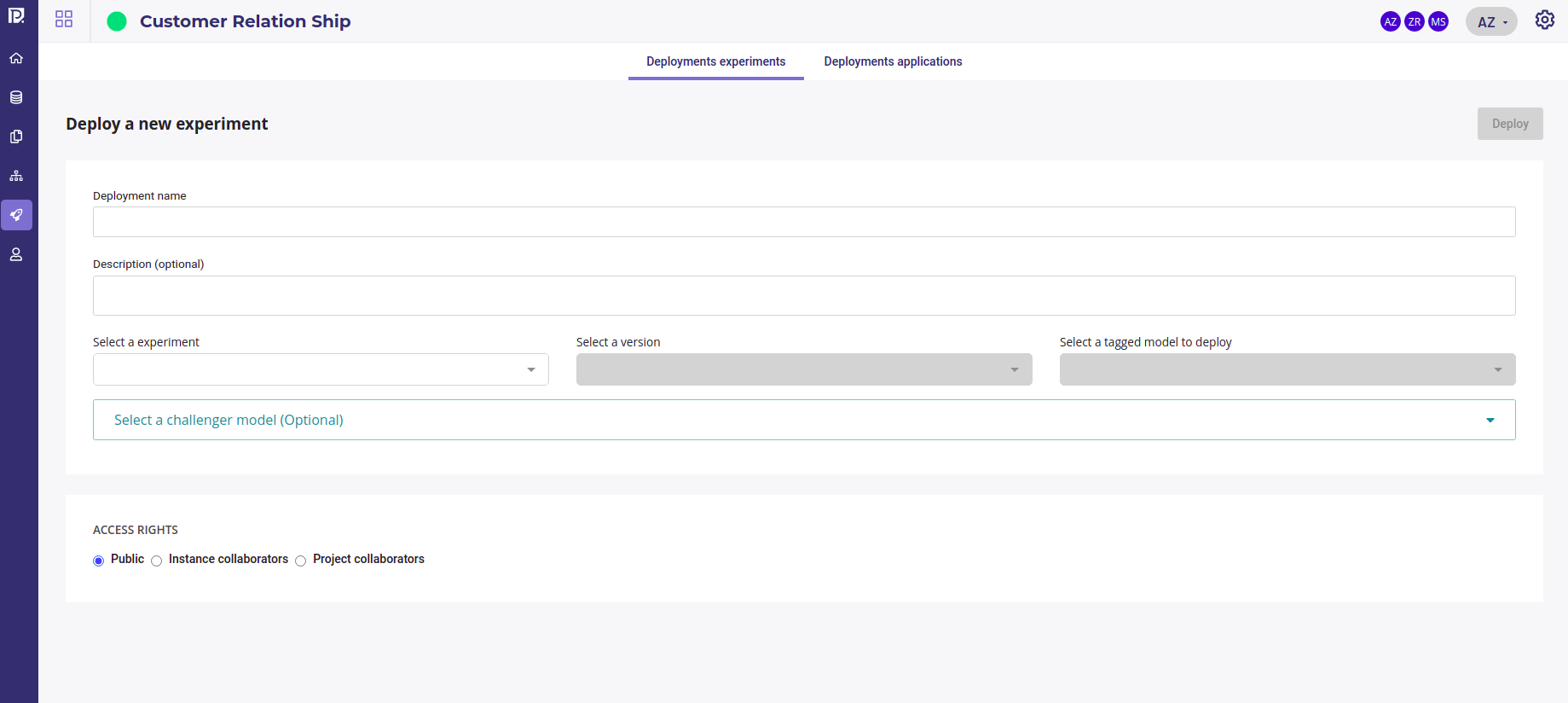
Create a new deployment
In addition to give it a name and a description, you must :
- select one of your experiment
- select a version
- select a model from this version of your experiment
and you could select another version and another model of the same experiment taht will be deployed as Challenger model. This one will be called each time you main model is called and it’s response will be recorded next to those of the main model in order to compare them and maybe be switch them.
When deploying a new experiment you need to grant access :
- public : everybody can call your model
- Instance collaborators : everybody on the instance can call your model ( note : every user on cloud.prevision.io share the same instance )
- Project collaborators : only your project’s collaborators can call your model
Once you click on the deploy buttont, the model you chose will be deployed. You can check its status in the list of deployments or in the deployment page.
Inspect and monitor a deployed experiment¶
The deployment page is available as soon as the experiment is deployed. On each deployment page lie five sections.
General¶
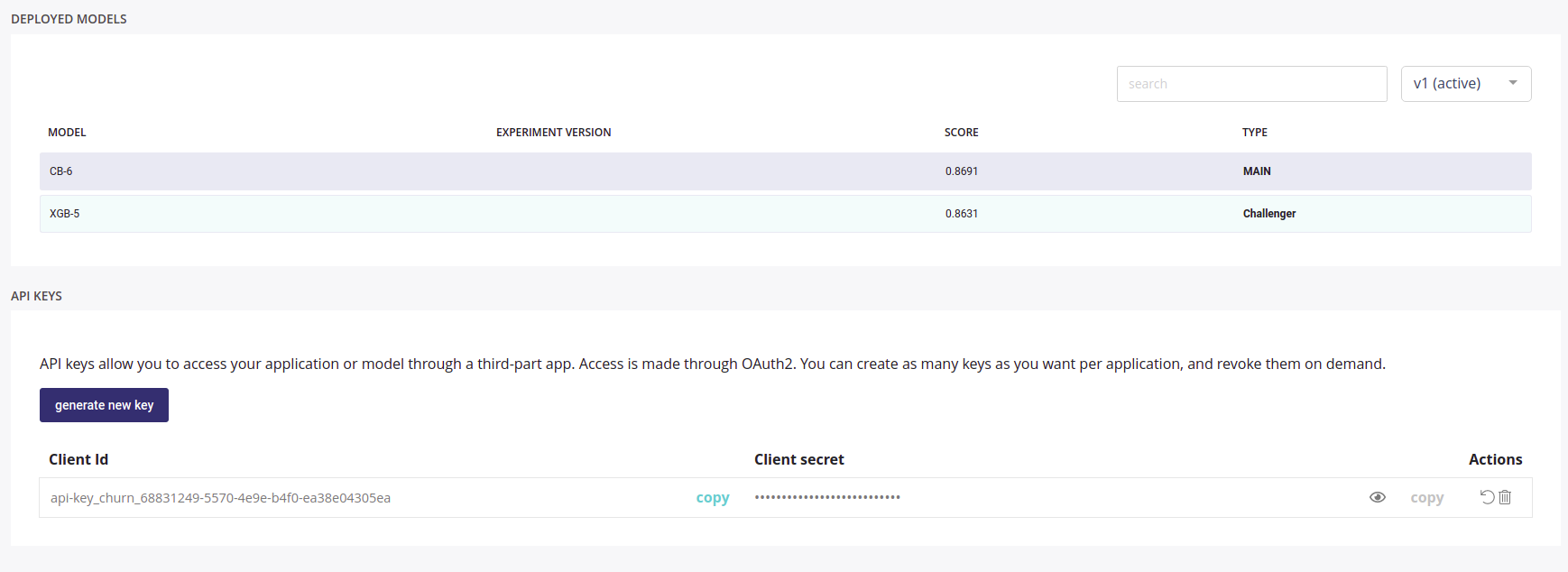
General info about your deployment
The general tab will show you :
- Creation date of your deployment
- Current version of your deployment
- A link for using the model with a simple form
- deployment status
- main model status
- challenger model status
- a link to the documentation of model API
- the access you granted
And
- a drift chart : a chart showing distribution of the training data vs distribution of the data predicted since deployed
- a summary of the models deployed
- an API key generator than you can share to others applications in order to call your model
Monitoring¶
The monitoring section will show you a selection of chart of :
- the data sent to your models
- the prediction done by your models, both main and challenger if you deployed a challenger model
- the drift of your input data
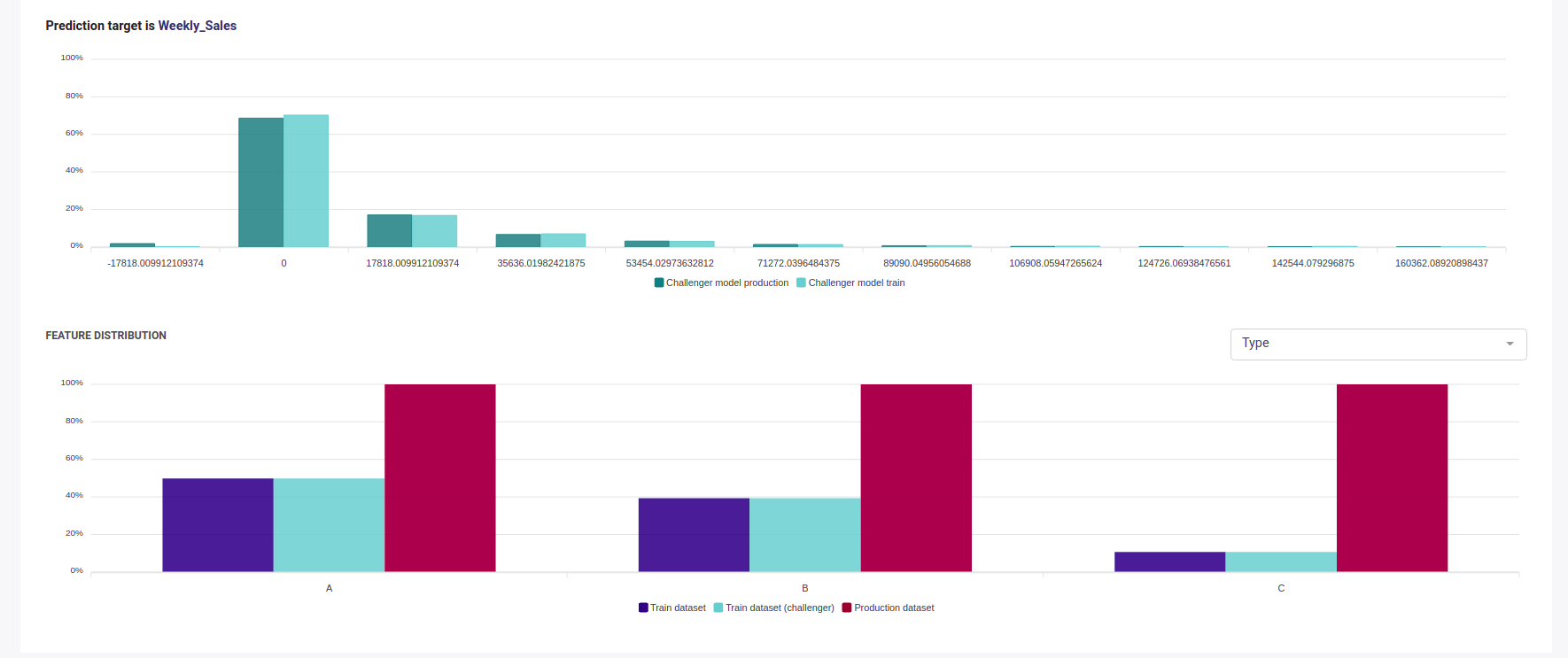
Model monitoring
Monitoring this chart let you decide when your model becomes obsolete and you should schedule a retrain.
Predictions¶
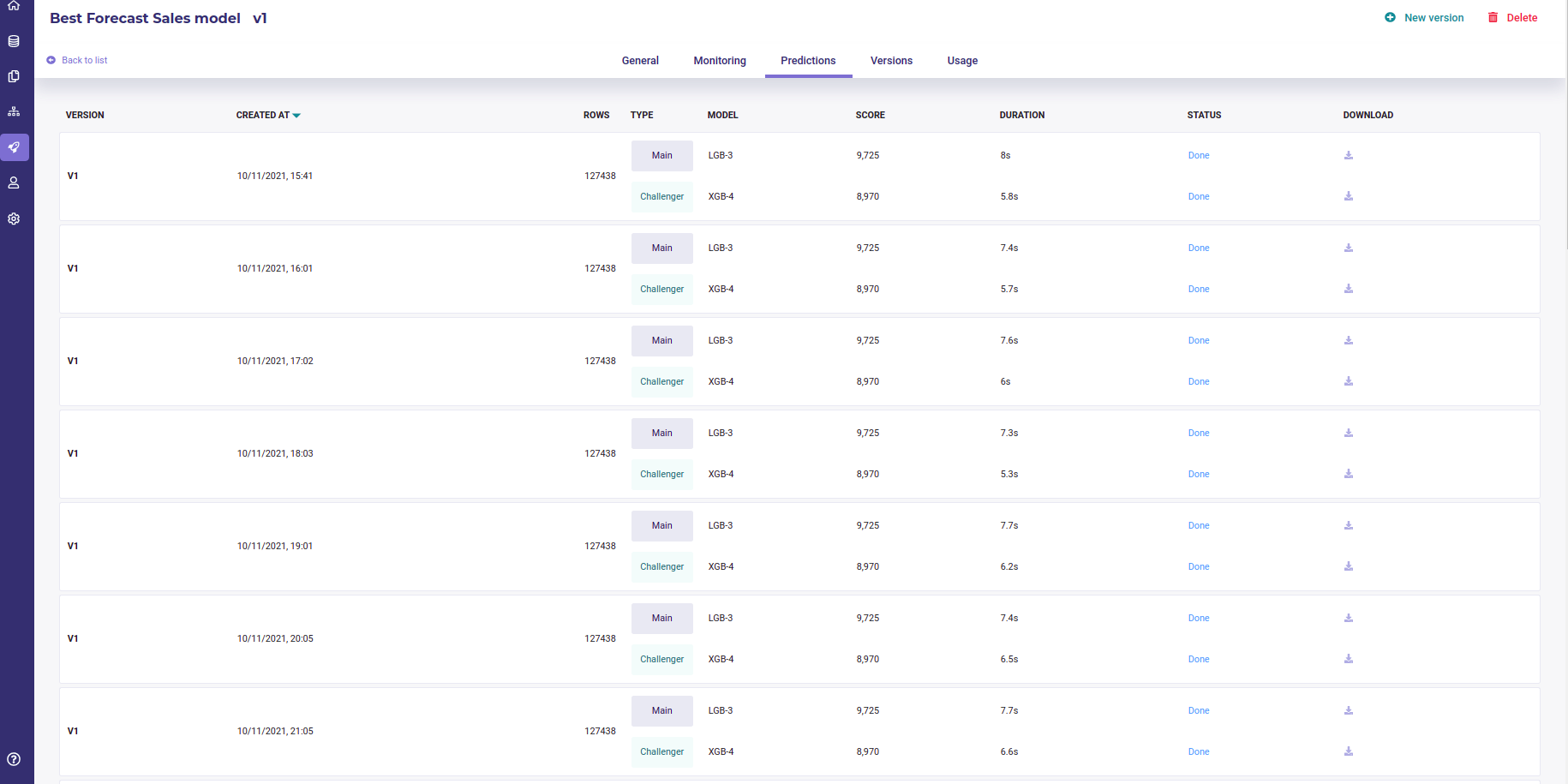
Predictions list
The Predictions tab is where you will find all the predictions scheduled in a pipeline done with your deployed experiment. When an experiment is deployed, it can be used in a pipeline and this, can be schedule, to be deliver in an external database each monday for example. Each time a prediction is ran in a pipeline, a file is generated both for the main model and the challenger model and they can be downloaded for further inspection from this section.
Versions¶
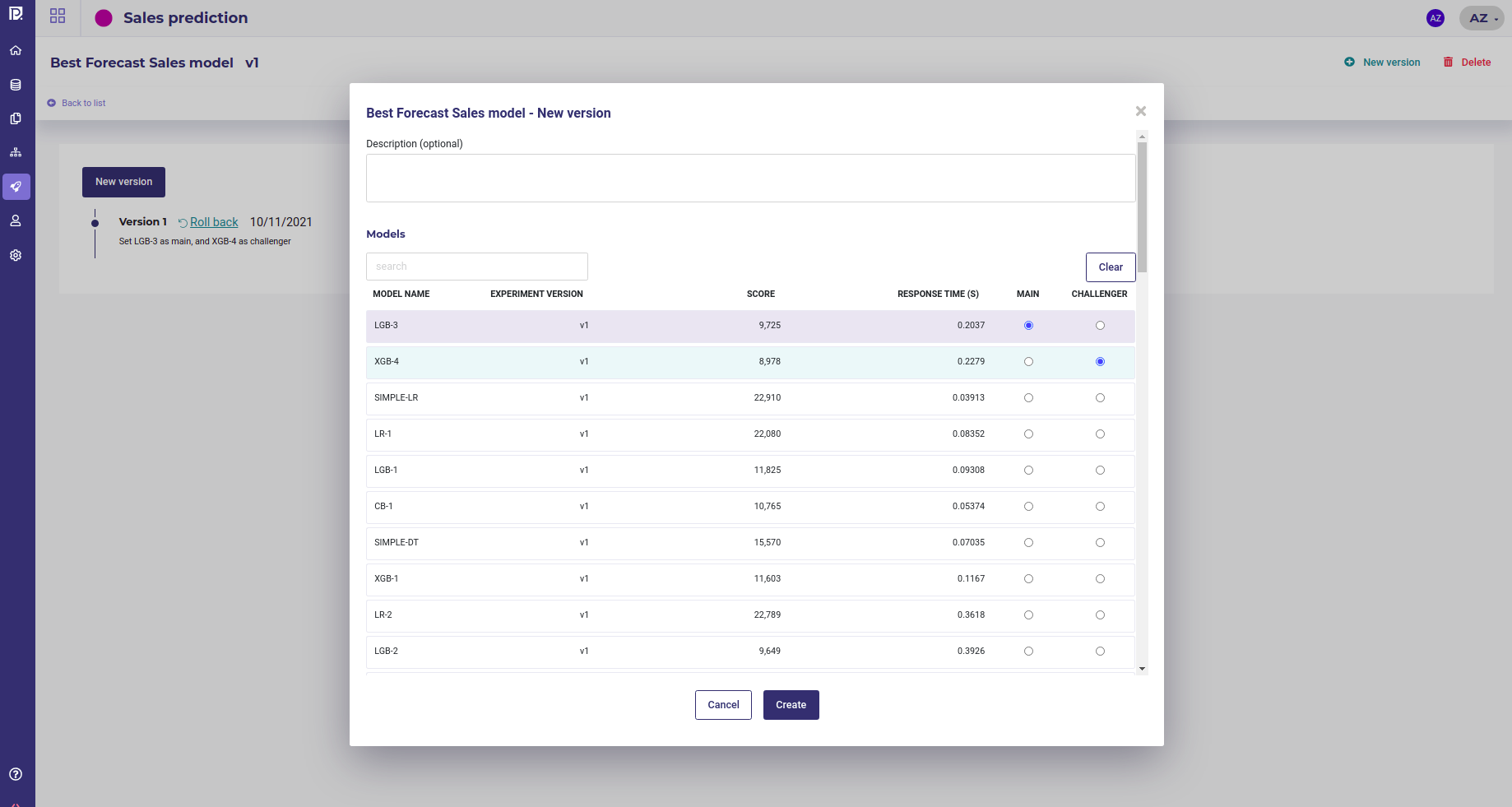
Managing version of a deployment
At any moment you can change the model of your experiment that is called, picking it in any version of your experiment. By doing so, you will replace the models called when someone use your deployed experiment without anyone noticing or having to change its client call.
When creating a new version you can change both the main model and the challenger model. You can rollback to a previous version of your deployment just by clicking on the Rollback link. The version clicked will then be used again to do predictions.
Usage¶
The usage section displays CPU and memoru usage of your deployed experiment.
Edit and remove a deployment¶
You can not edit a deployment but you can remove it either from the list of deployment, with the 3-dots menu on the right of the list items, or on the individual page of each deployment with the Delete button.