AutoML¶
Prevision.io platform can train model based on your experiment parameters. The AutoML Engine make analysis of your dataset and :
- builds the best feature engineering given your datatype ( for example : convert text and images to embedding or build lags auto on time serie )
- choose the fittest algorithm given your data
- choose the best parameters for each algorithm
- may blend and combined many model to get performance
When choosing AutoML, you can tune some configuration but the most important are those on the « Basics » tabs :
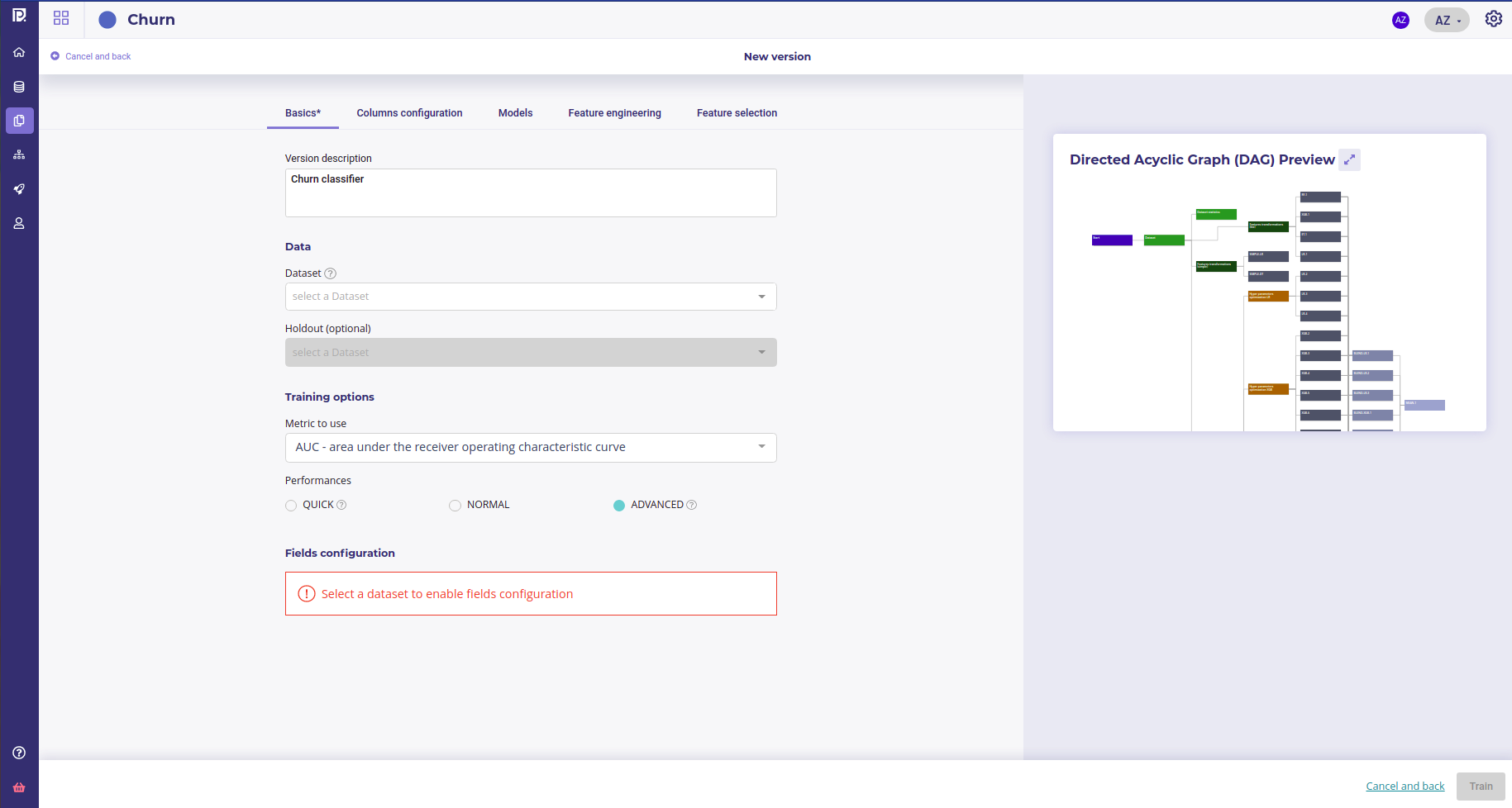
Basic configuration
- the Metric to optimise ( see our guide on how many time you should spend on choosing the metrics )
- the performances profil :
- Fast: get a result as fast as possible
- Normal : Spend more time in hyper opt
- Advanced : get the best result ( spedn many time son hyper opt and blending models )
General advice is to start project with a « Fast » profile and go for advanced train when the problem and features are completely defined.
Most of the configuration is common accross the training type and Data types except the metrics that depends on the type of problem, but some of them have specificities, especially on the metrics and the available models
Note that when you create a new experiment, you will be prompted to create a first version
Empty experiment
See more about each type of training on dedicated section :