Structured Data¶
Tabular data use data in columns to build model. There 3 kind of probleme type, Regression, classification, multi classification and a special one, text similarity
This section explains the parameters for regression, classification and multi classification. For text similarity, see the dedicated section
Basics tabs¶
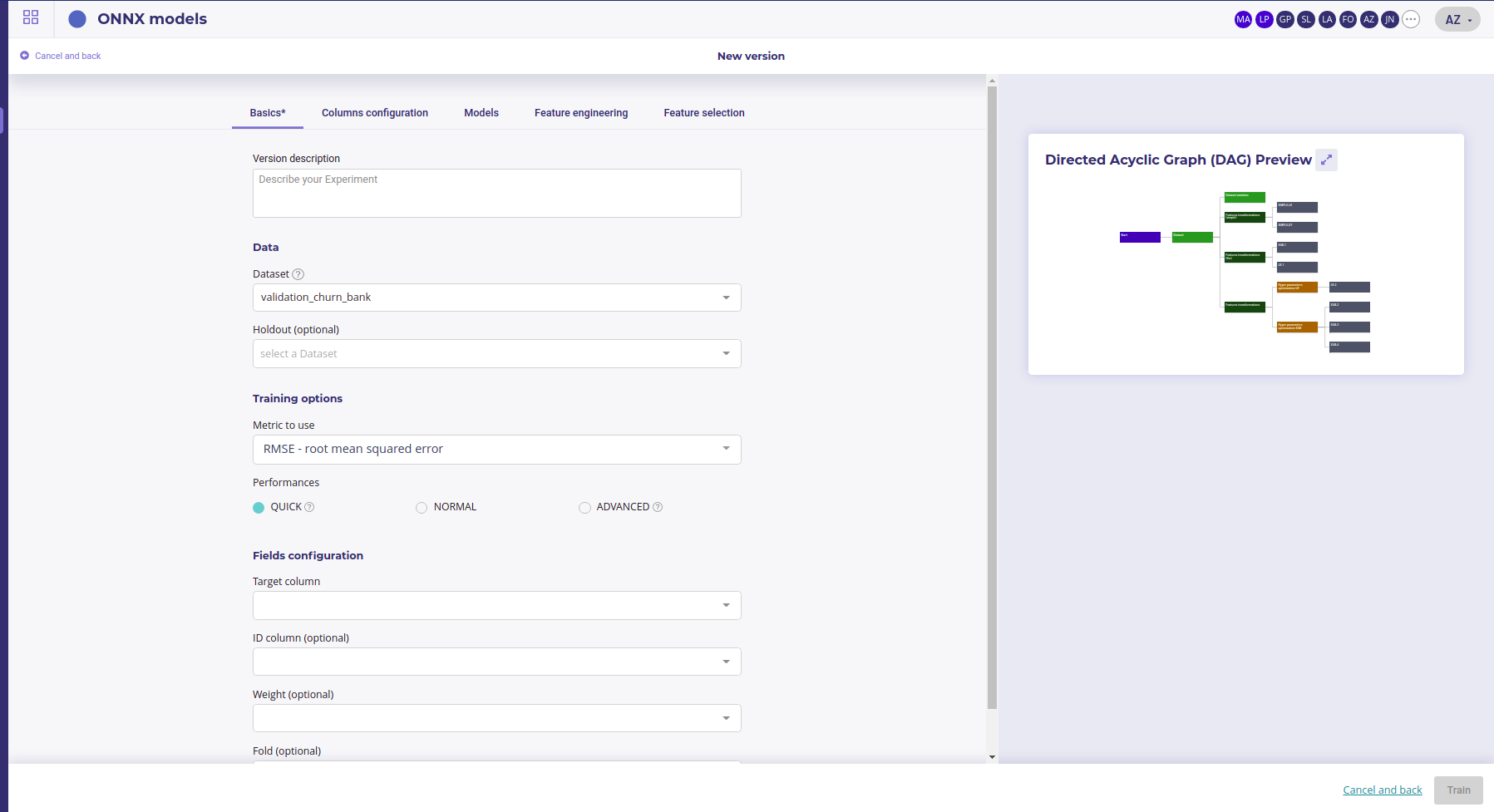
Basics configuration
The basics tab group all the important parameters :
- dataset : the dataset from your datas assets to train on. This parameter is mandatory for automl
- holdout : holdout is another dataset that will be used to evaluate your model. It should have the same features and target than the trainset but with sample never seen in the trainset. It is optional but strongly recommended, especially at the end of your experiments, to check your model stability
- metrics : the options depends on your training type but you may choose one of the standard Machine Learning metrics for objective
- Performances : quick for qui result, Advanced for best result. Be aware that advanced option could lead to more thant 24 hours of training if the trainset is big. Quick get result in less thatn 3 hours in mot of case.
- Target : set the column of your trainset to predict. Note that the platform filter available target based on your problem type ( example : it expects the target too have 2 modalities only if the problem is a classification )
- ID Column : you can set a column as an id. It must have only unique values The column set as an id will not be used as a feature and will be repeat on subsequent prediction to serve as a join column. If you do not set an ID column, an index will be generated.
- Weight : you can set a column to be used as a Weight column for sample. The sample with large weight will be favored during the training. If you do not set weight, the system apply a balanced trainign, meaning it applies larger weight to the less frequent target modalities.
- Fold : Fold colum will be used to generate cross validation. If you do not know how to generate correct fold, leave this empty. Otherwise, you may put a fold number (integer ) in this column and the Cross Validation will be run by splitting the dataset against this folds.
The two mandatory parameters are Dataset and Target. Once had set them up you can proceed and launch train by clicking on the trian button in the right-lower corner.
Columns configuration¶
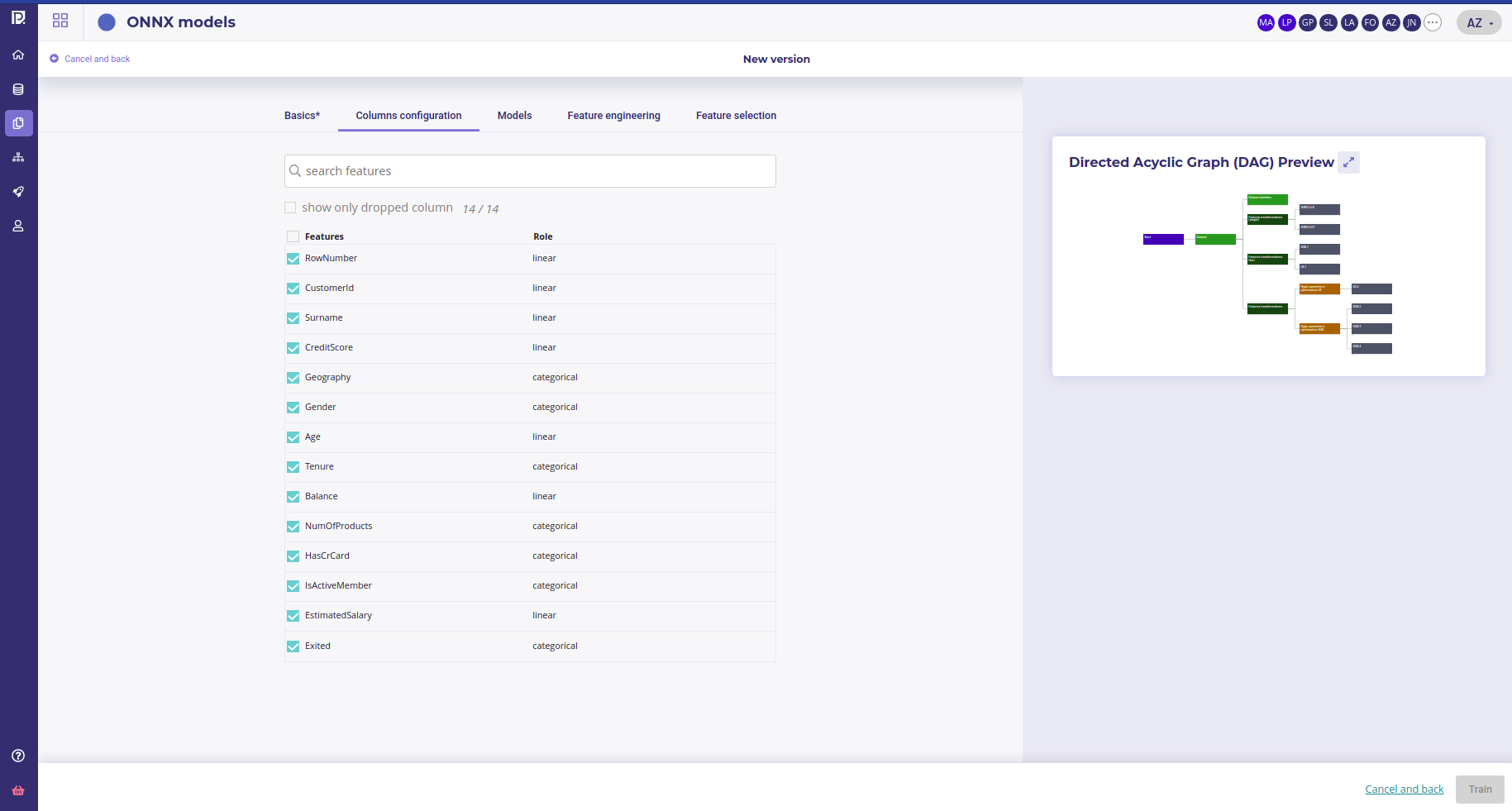
Basics configuration
The second bottom left panel allows you to ignore some columns of your dataset. To do it, just deselect unwanted features. Please note that you can search by features name the columns you want to unselect and use the “select/unselect all” checkbox to apply your choice to the selection.
Why drop features ?
In most of case, you should not drop any features. The Prevision Platform can handle up to several thousands of features and will keep those meaningful to build its models. Yet, there is two ase you would drop some features :
- Some Features has too much importance in the model and you suspect that it is in fact a a covector of the target, or that you have an important leakage. If you see that your simplest model (Simple LR ) perform as well as complex one and that some feature as a big feature importance, drop it
- you want to get some result fast. Dropping features allows for faster training. If you suspect that some features bears low signal, drop it at the start of your project to iterate faster
Models¶
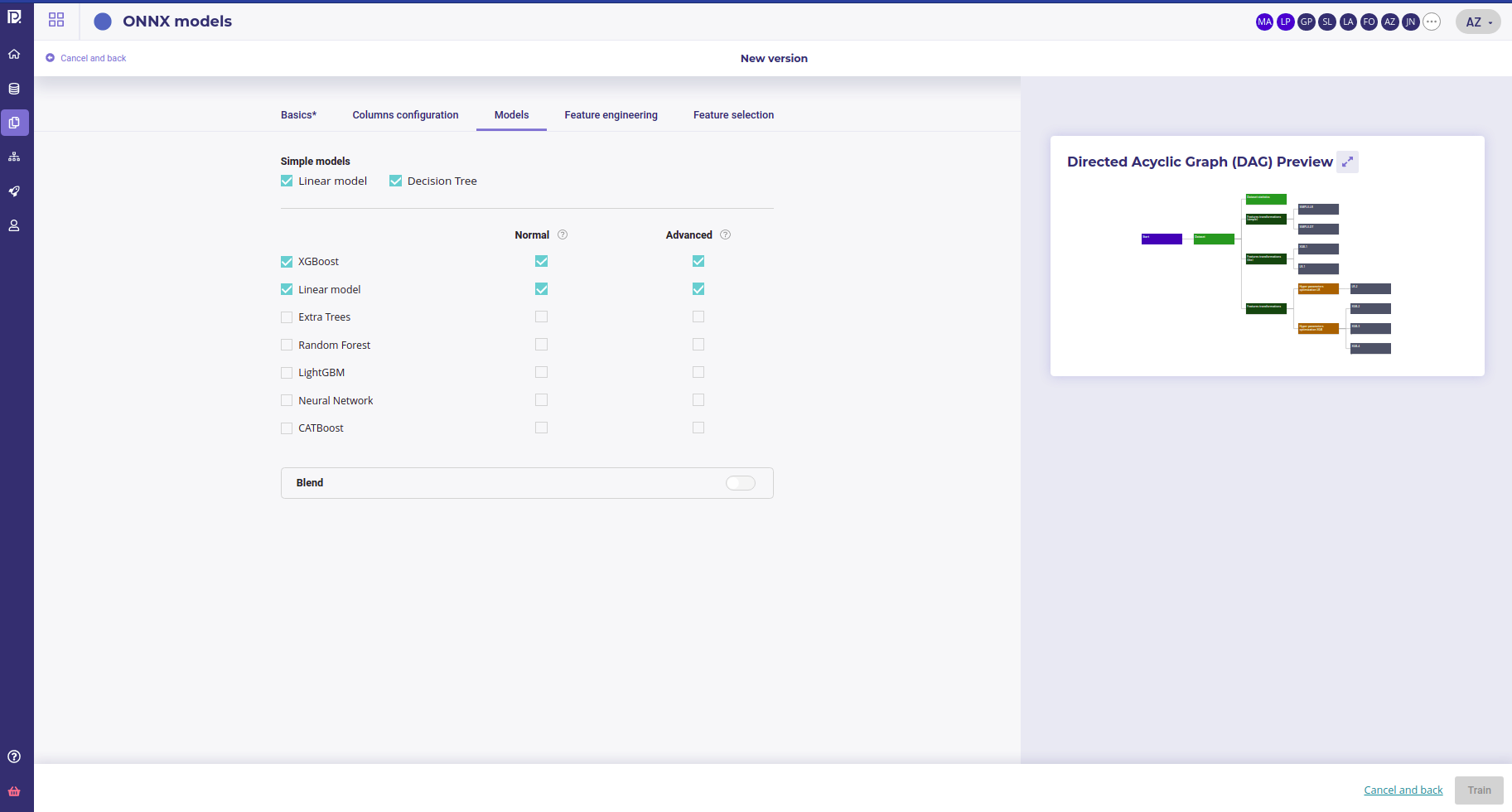
Model tab
The model selection area allows you to select the type of model you want to train. You got 3 sections.
Simple Models¶
Simple models are models done with no complexe optimisation and using simple algorithm, a linear regression and Random Forest with less than 5 split. They allow to check if the problem is treatable with very simple algorithm instead of fancy Machine Learning. Moreover, simple model generate :
- a Chart that explain model and is human readable
- python code to implement it
- SQL Code to implement it
You can unselect simple model but it is recommended to keep them when starting a project and watch how good they perform vs more complex model. If a simple Decision Tree performs as good as a Blend of XGBoost, or only marginally worst, favor the simple model.
Model Selection¶
You can choose the algorithm type that the automl engine will use. The more you select, the longer is the train. All the selected algorithm will be used in blend
Note that only if :
- there is at least one column with text
- the probleme type is a classification or a multi classification
you can select Naive Bayes Model
Blend¶
Blending model is a powerful technique to get the most performance yet it can be quite long to train. Blend use a model over all the others to merge and combine them in order to get the best performance. Switch the option if you want to blend your models but be aware that resulting train will last very long.
Feature engineering¶
In this section, you could select more feature engineering ( or unselect some ).
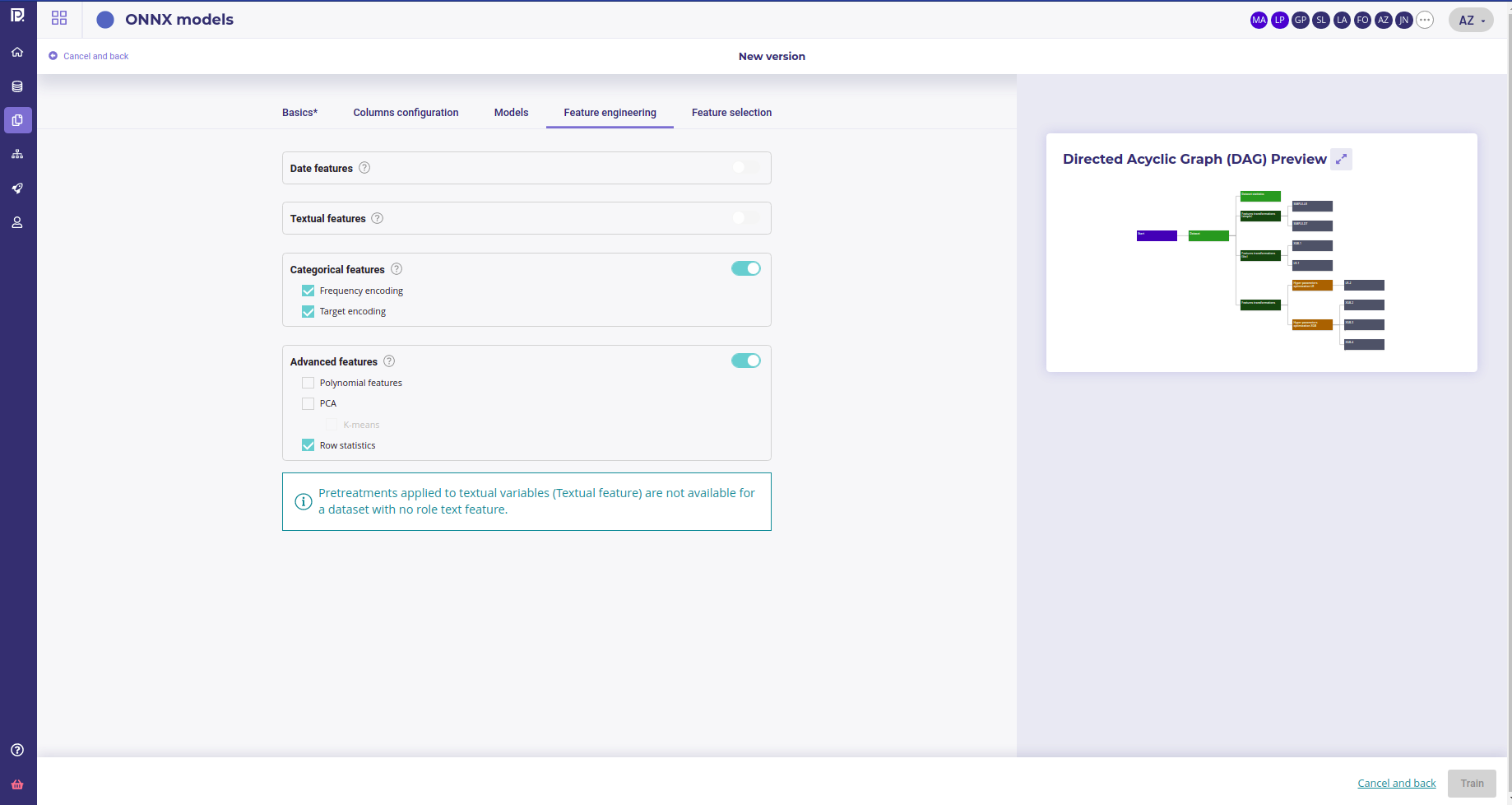
Model tab
Four kinds of feature engineering are supported by the platform. :
- Date features : dates are detected and operations such as information extraction (day, month, year, day of the week, etc.) and differences (if at least 2 dates are present) are automatically performed
- Textual features :
- Statistical analysis using Term frequency–inverse document frequency (TF-IDF). Words are mapped to numerics generated using tf-idf metric. The platform has integrated fast algorithms making it possible to keep all uni-grams and bi-grams tf-idf encoding without having to apply dimension reducing. More information about TF-IDF on https://en.wikipedia.org/wiki/Tf%E2%80%93idf
- Word embedding approach using Word2Vec/Glove. Words are projected a dense vector space, where semantic distance between words are : Prevision trains a word2vec algorithm on the actual input corpus, to generate their corresponding vectors. More information about Word embedding on https://en.wikipedia.org/wiki/Word_embedding
- Sentence Embedding using Transformers approach. Prevision has integrated BERT-based transformers, as a pre-trained contextual model, that captures words relationships in a bidirectional way. BERT transformer makes it possible to generate more efficient vectors than word Embedding algorithms, it has a linguistic “representation” of its own. To make a text classification, we can use these vector representations as input to basic classifiers to make text classification. Bert (base/uncased) is used on english text and Multi Lingual (base/cased) is used on french text. More information about Transformers on https://en.wikipedia.org/wiki/Transformer_(machine_learning_model). The Python Package used is Sentence Transformers (https://www.sbert.net/docs/pretrained_models.html)
- Categorical features:
- Frequency encoding: modalities are converted to their respective frequencies
- Target encoding: modalities are replaced by the average (TARGET, grouped by modality) for a regression and by the proportion of the modality for the target’s modalities in the context of a classification
- Advanced features:
- Polynomial features: features based on products of existing features are created. This can greatly help linear models since they do not naturally take interactions into account but are less usefull on tree based models
- PCA: main components of the PCA
- K-means: Cluster number comming from a K-means methode are added as new features
- Row statistics: features based on row by row counts are added as new features (number of 0, number of missing values, …)
Please note that if you don’t have a feature of one of these feature types in your train dataset, the corresponding feature engineering toggle button will be disable. Also please note that textual features pretreatments only concerne advanced models and normal Naive Bayes model
Feature selection¶
Feature Selection
In this part of the screen you can chose to enable feature selection (off by default).
This operation is important when you have a high number of features (a couple hundreds) and can be critical when the number of features is above 1000 since the full Data Set won’t be able to hold in RAM.
You can chose to keep a percentage or a count of feature and you can give a time budget to Prevision.io’s to perform the search of optimal features given the TARGET and all other parameters. In this time, Prevision.io will subset the feature of the Data Set then start the classical process.
The variable selection strategy in Prevision.io is hybrid, depends on the characteristics of the dataset and the time available.
- It is hybrid because it combines both so-called filtering methods, encapsulation methods and integrated methods. The filtering methods perform the selection of entities independently of the construction of the classification model. Encapsulation methods iteratively select or eliminate a set of entities using the metric of the classification / regression model. In built-in methods, feature selection is an integral part of the classification / regression model.
- It depends on the characteristics of the dataset and the time
allotted. In fact, depending on the volume of the dataset, a small
data strategy is applied for a dataset of less than 8 GB, fully in
memory. Otherwise, a big data strategy is applied.
- In a small data situation, a first filtering approach is carried out consisting in filtering the variables of zero variance, the duplicated variables, the intercorrelated variables beyond 99% and the variables correlated to the target variable beyond 99% . Depending on the time remaining available, a second so-called encapsulation method is carried out using a LASSO-type regularization on the entire dataset by cross validation with the aim of optimizing the metric selected when the use case is launched.
- In a big data situation, as time permits, several row and column samplings are carried out and the stages of filtering, encapsulation method and integrated methods completed by a reinforcement learning strategy are successively launched. . The variables are then ranked in order of priority according to the different approaches tested and the top variables, at the threshold defined by the user, are sent to the various algorithms of Prevision.io.