Features¶
In this section you will find any information relative to the dataset used during the train.
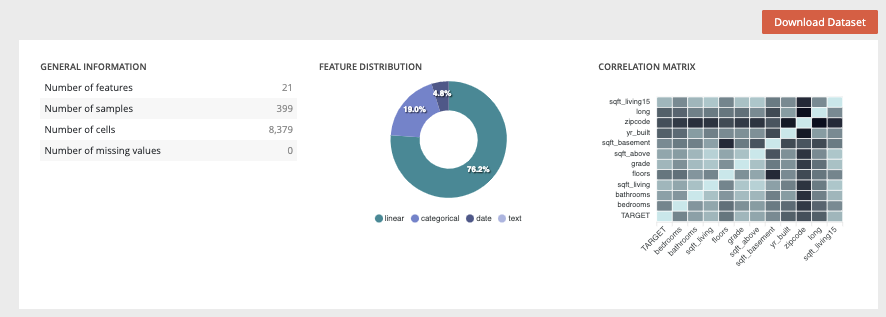
On the top panel, you will find generic information about the dataset used during the train such as the number of columns, number of samples and number of cells or the usecases using this dataset.
You can also download the dataset used for the training by clicking on the “download dataset” button on top of the page.
Two graph are also displayed showing :
- the feature distribution regarding the feature type (linear, categorial, date or text). This distribution is automatically calculated when uploading a dataset into the platform
- correlation matrix showing the correlation coefficients between variables. Each cell in the table shows the correlation between two variables
Under this top panel, two tabs are available :
- Features analysis : table displaying features information calculated after the upload of the dataset such as the % of missing value.
- Dropped features : In this tab, you will find a list of all features you dropped for the usecase training during the usecase configuration
By clicking on a feature name you will be redirected to feature detail page
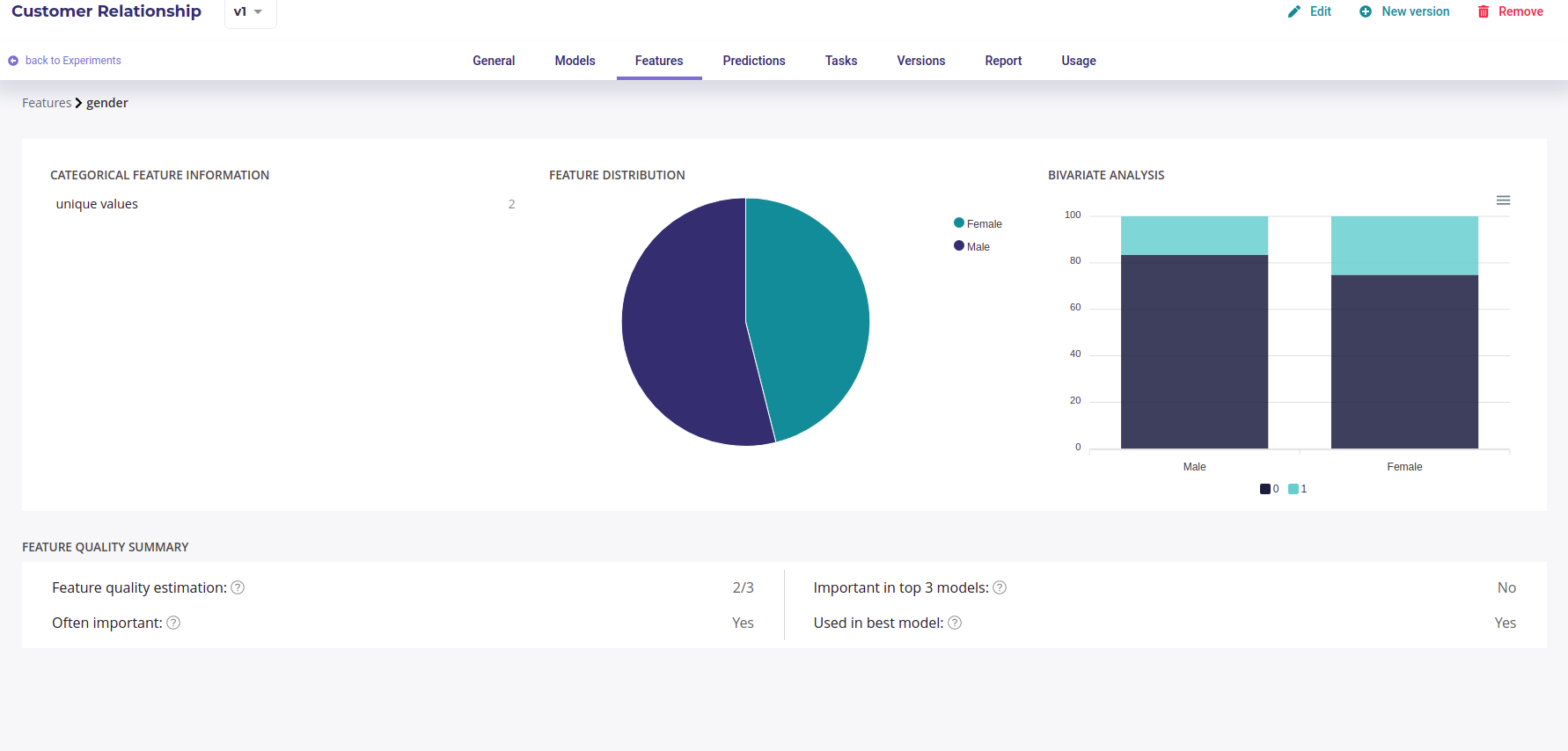
Feature detail
The feature detail has some statistics chart about the features, its relation to the target and its signal power for the submitted problem