Full ML pipeline: From data collection to deploying using Prevision.io¶
How to release a model across all your organisation in one morning ( and stop spending 24 man-month on a model that will never go into production ) ?
What is this Guide about ?
This guide is walkthrough for delivering ( very ) quickly a complete Machine Learning Project by using the Prevision.io platform
The guide details each standard step of a Machine Learning project, from data to model usage across the organisation, and shows how to accomplish them in the platform.
We use historical sales data and intend to build a sales forecasting model.
What’s in this guide ?¶
Starting point¶
This guide assumes that :
- you got a Prevision.io platform
- the IT Teams put some historical sales data in a database and gave you access ( but if not, csv files are provided below for the sake of this guide )
- An objective has been defined by the Line of Business.
Steps¶
The steps of our guide will be :
| Step | Name | Goal | LoB | IT | Datalab | Output | time spent |
|---|---|---|---|---|---|---|---|
| 1 | Data acquisition | Get the historical data for training Machine Learning Model | No | Yes | Yes | dataset | 5mn |
| 2 | Feature engineering | Prepare the dataset | No | No | Yes | Holdout and validation strategy ( fold ) | 20mn |
| 3 | Define the problem | Define a metrics that reflects LoB process | Yes | No | Yes | A consensus | As Much as possible |
| 4 | Experiment | Train models | No | No | Yes | ~100 Models | 25mn |
| 5 | Evaluate | Get the fittest model | Yes | No | Yes | A selection of 3 to 4 models that go in production | As Much as possible |
| 6 | Deploy | Share the model accross the organisation | No | No | Yes | Webapp for human, API for machine | 5mn |
| 7 | Schedule | Schedule predictions | Yes | Yes | Yes | Prediction delivered each Monday a 9:00 am in CRM software | 20mn |
| 8 | Monitor | Track the model in situ | Yes | No | Yes | Dashboard | As Much as possible |
| TOTAL | 1h15 |
For each of them, the guide explains what to expect from this steps and how we accomplish it.
Results¶
At the end of this guide :
- LoB will get a weekly sales forecast each Monday at 09:00 AM
- LoB will get a simulator for testing hypothesis over the model
- Applicative team will get an API for calling the model in their own Application
- IT Team will get a dashboard to monitor model Quality of Service
So what’s the job of a datascientist anyway ?
Datascientist is not a developper, even if her or his main tools is code.
Datascientist salary ( and scarcity ) are quite high. If your datascientist spends most time coding models, you should get a developper.
The time spent of a datascientist in an organisation should be spent with the Business owner on the 3th and 5th steps :
- DEFINE METRICS THAT REFLECTS A TRUE BUSINESS ISSUE
- CHOOSE THE MODEL THAT SOLVES THE PROBLEM THE BEST
This are the two most important points for a project to deliver R.O.I and using tools enables to focus on what matter.
You can open a free account to practice the following steps. When your account is ready, create a Project to host the assets
Create a new project
Data acquisition¶
First step to any project is getting historical data in order to train our Algorithm. As the name implies, Machine learning is all about reading historical data and let a computer model learns to predict a target.
The datas should have been loaded into a database by the IT Team and they have generated credentials for you. Once you have created your project, and selected it :
- go to the data section ( sidebar on the left )
- create a new connector and provided the credentials
- create a new datasource from the db and table of past sales
- Import it as a dataset
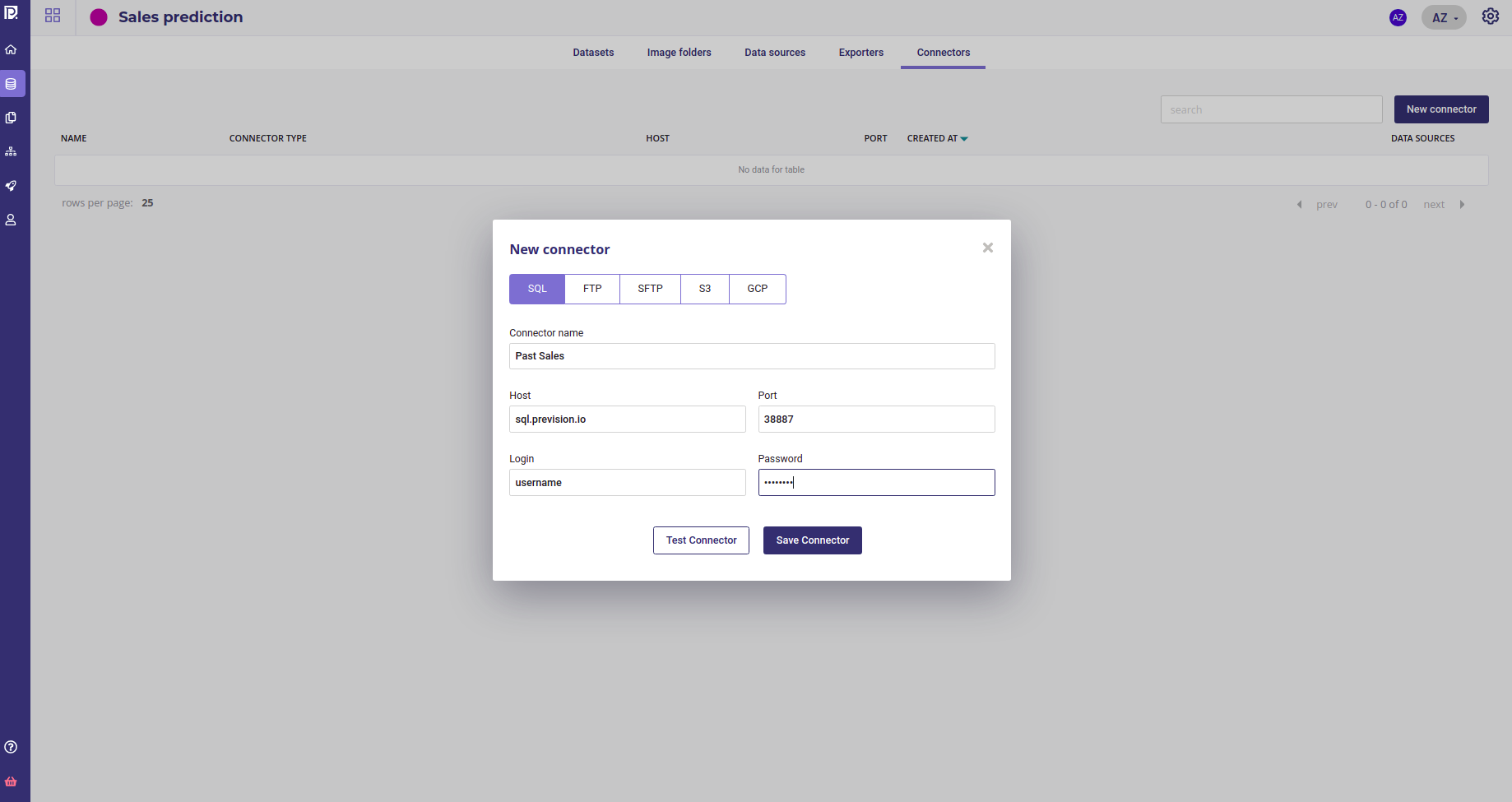
Create a new connector
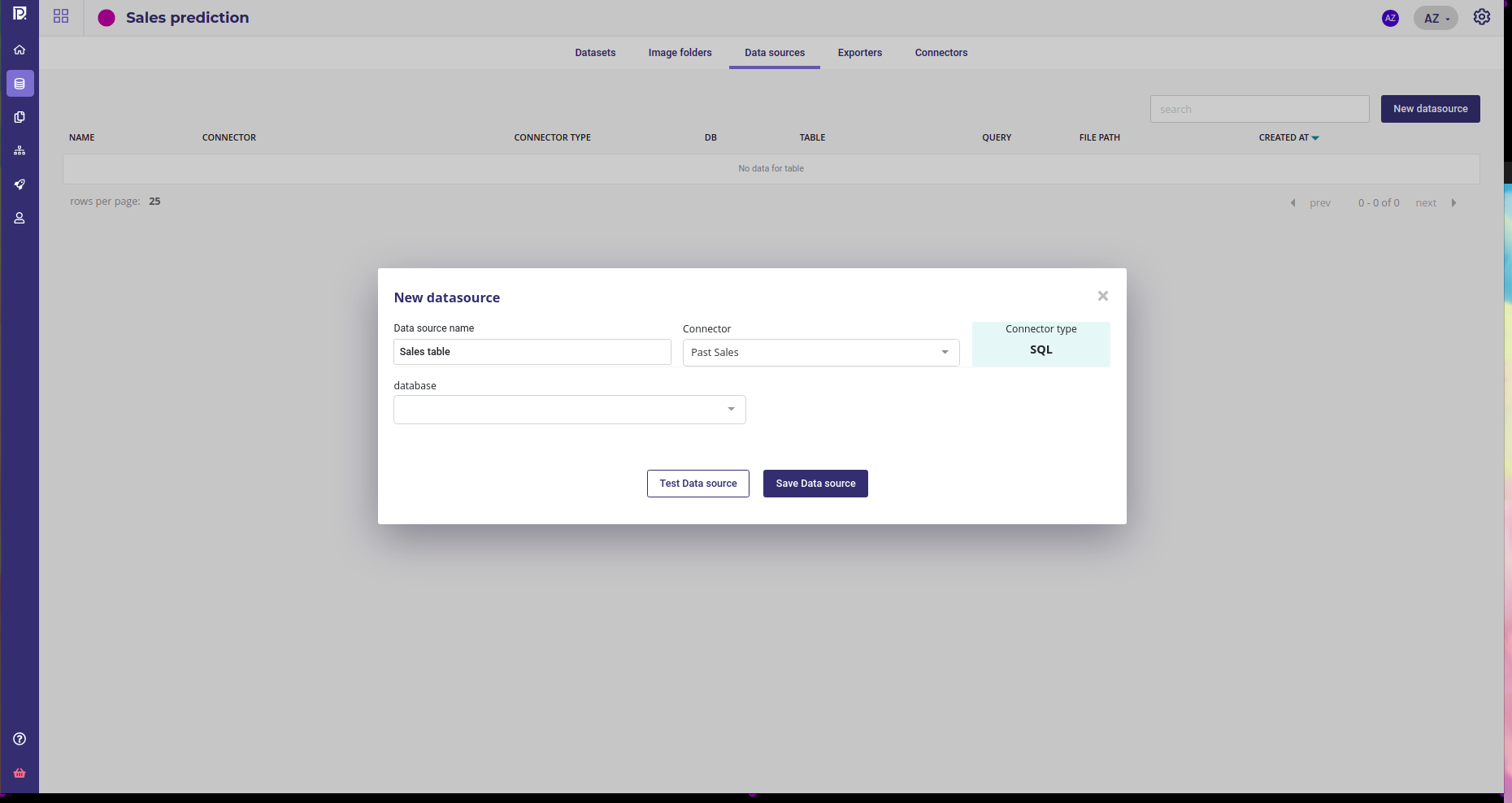
Create a new datasource
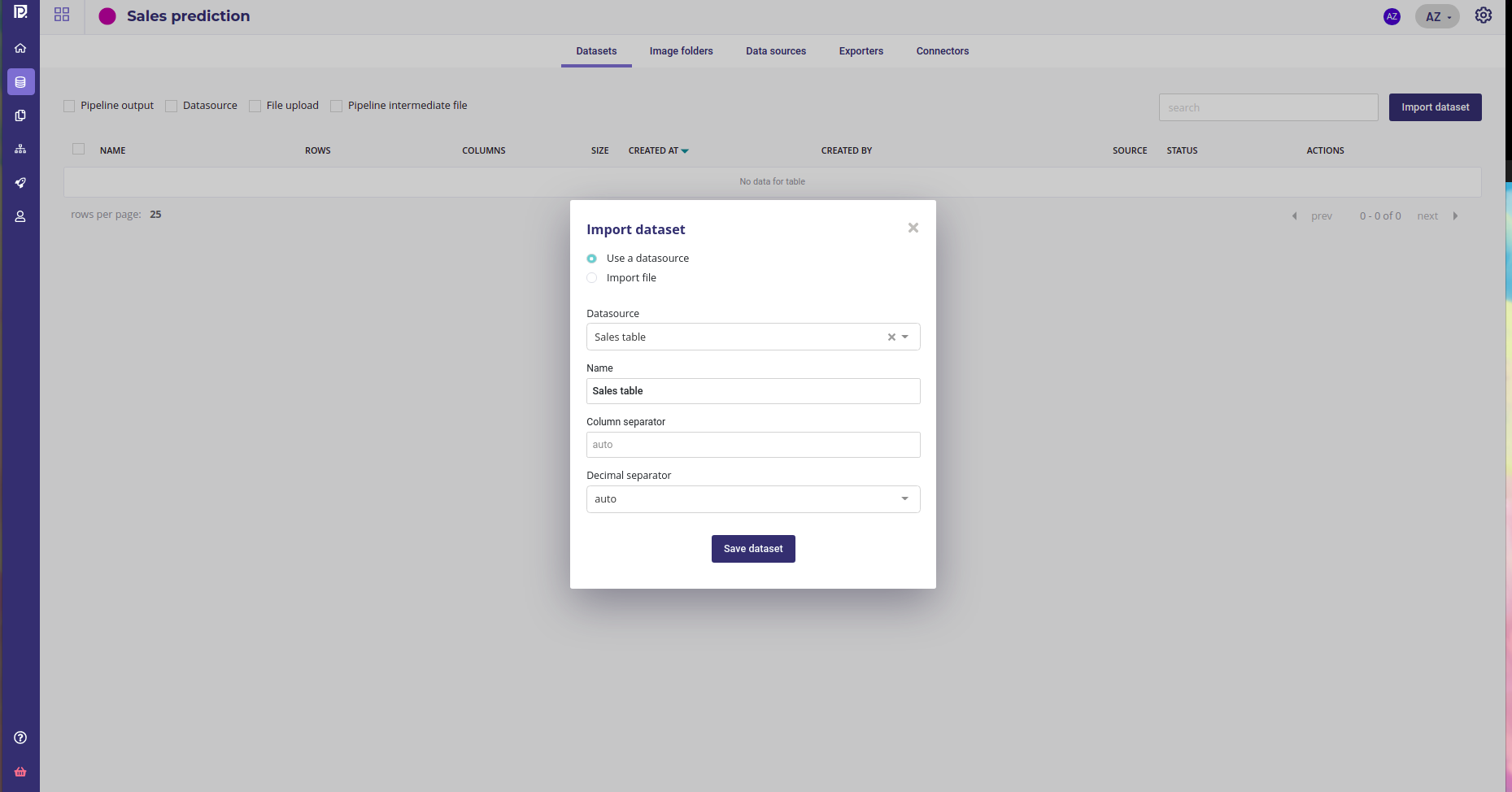
Import dataset
If available, you could import recent sales as an holdout dataset in order to validate and check stability of your model :
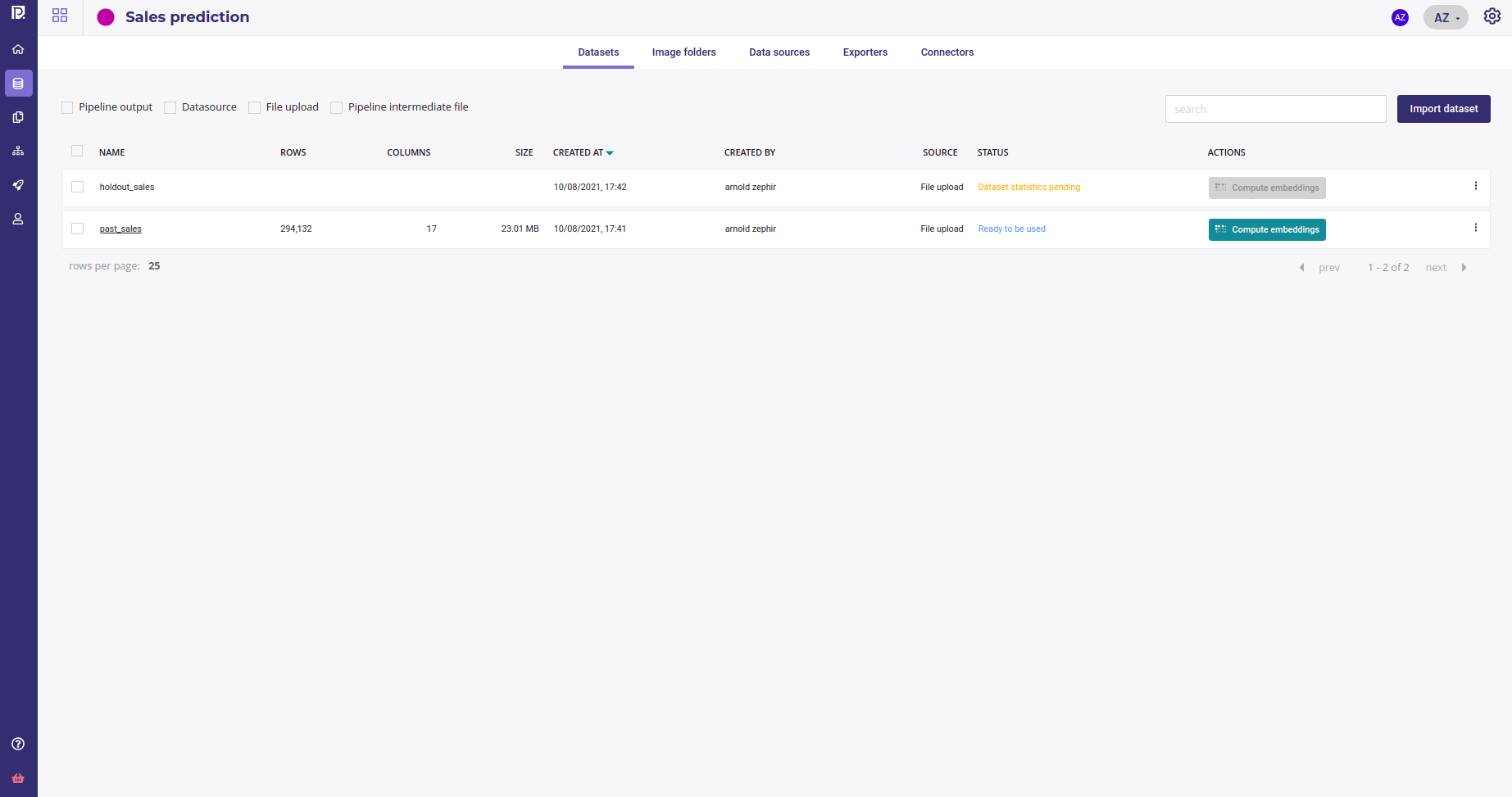
You got two datasets.
Data acquisition is done, you can now start to model
| Task | Status | Output | Time spent |
|---|---|---|---|
| Data acquisition | Done | one trainset, one holdout | 5mn |
Download data for testing by yourself¶
if you don’t have database credentials, you can use the following files. Just import file instead of using a datasource when importing dataset.
Feature engineering¶
Feature engineering is the addition or transformation of one or more features to create new features from the original dataset. In Prevision Platform, and most of the modern tools, feature engineering are done with components and pipelines yet in most of case you don’t need to add features as the AutoML engine makes all of the standard feature engineering by itself.
Here we are going to add a fold column on the date features in order to properly evaluate our model stability. A specific component has been developed by the datascience team starting from the Prevision Boilerplate and pushed on a private repo.
The component may now be integrated into the component library of the project.
Go to the pipelines section of your project and under the Pipeline Components tab, click New pipeline Component
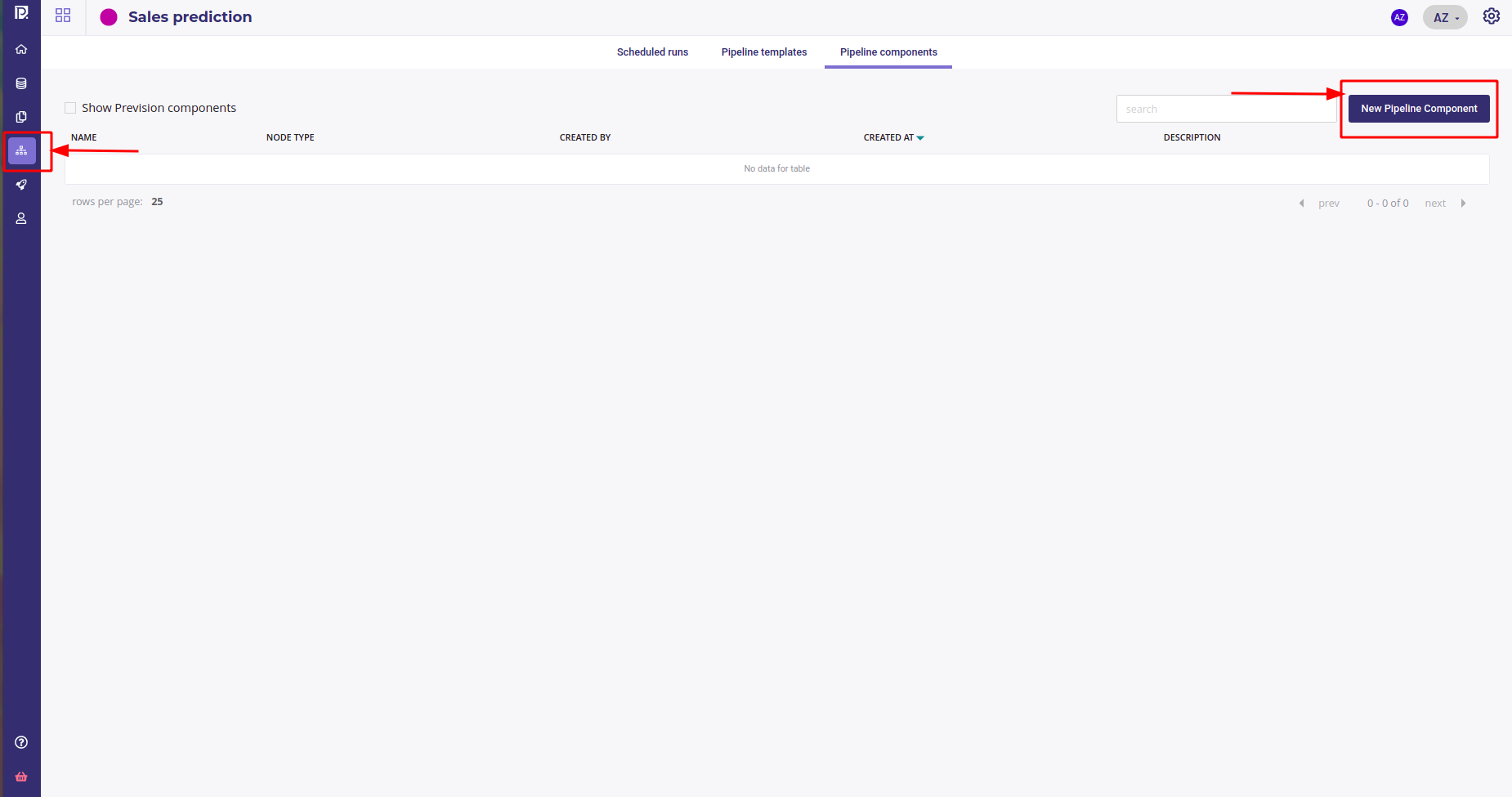
Create a new component
And select your repo and branch
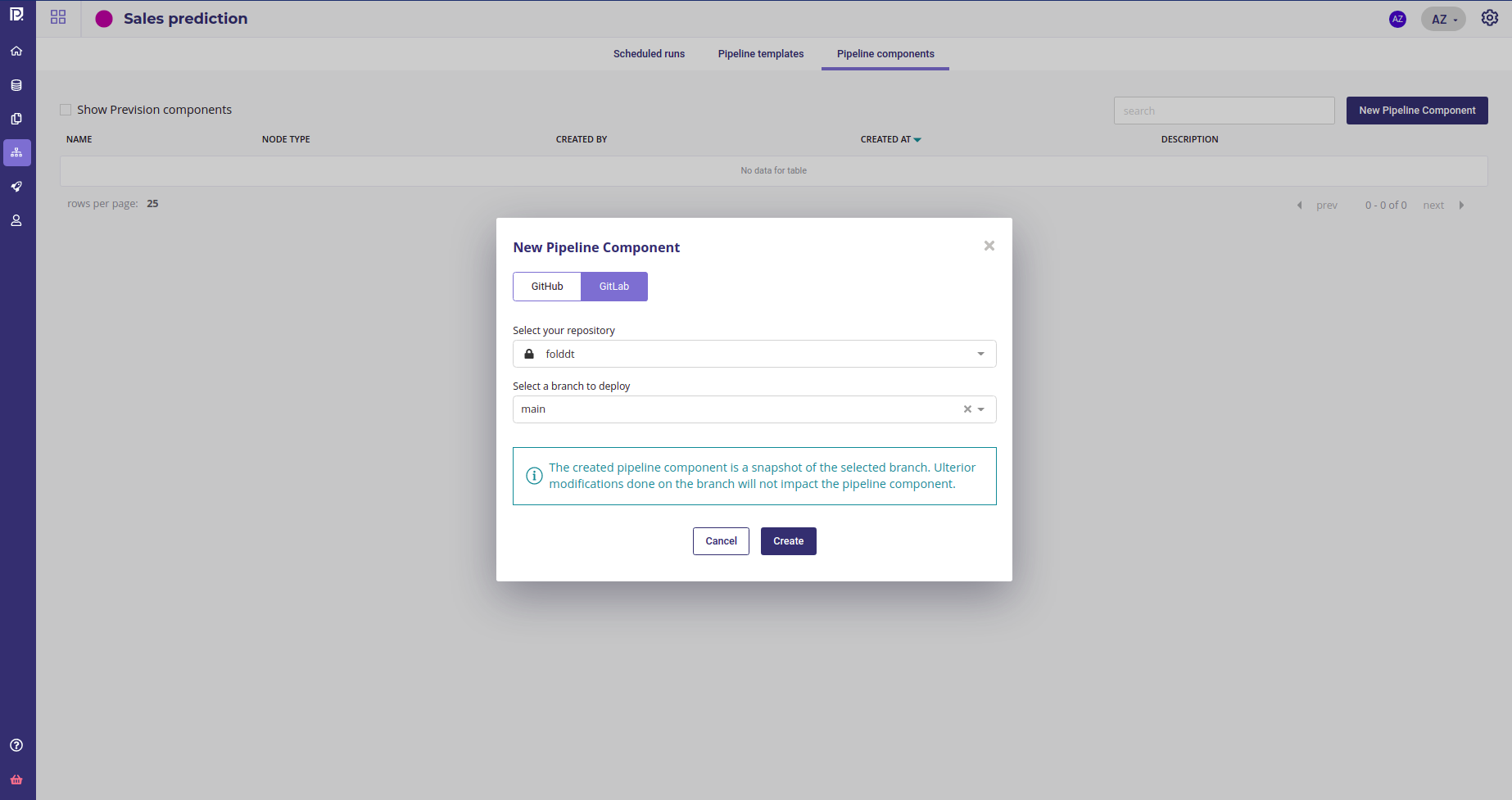
Import component from your repo
Once the component is built, its status will be ok and we can use it in a pipeline. Create a new pipeline template with three nodes :
- an import dataset, to read the trainset
- the newly created component ( « build fold » )
- a save dataset node to save the feature engineered dataset into you Data
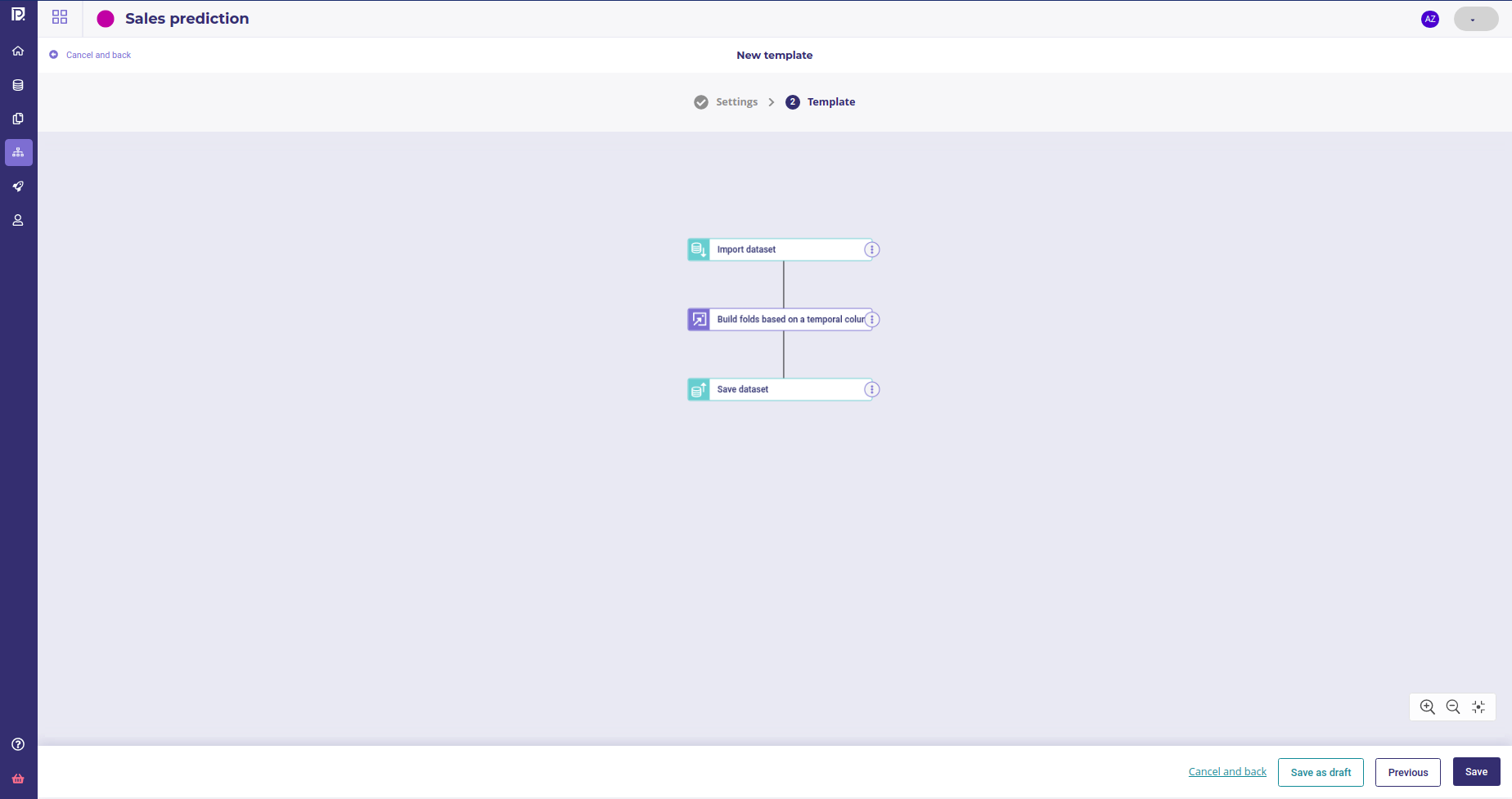
A simple feature engineering pipeline
Then create a new schedule run that you gonna execute manually once on your trainset.
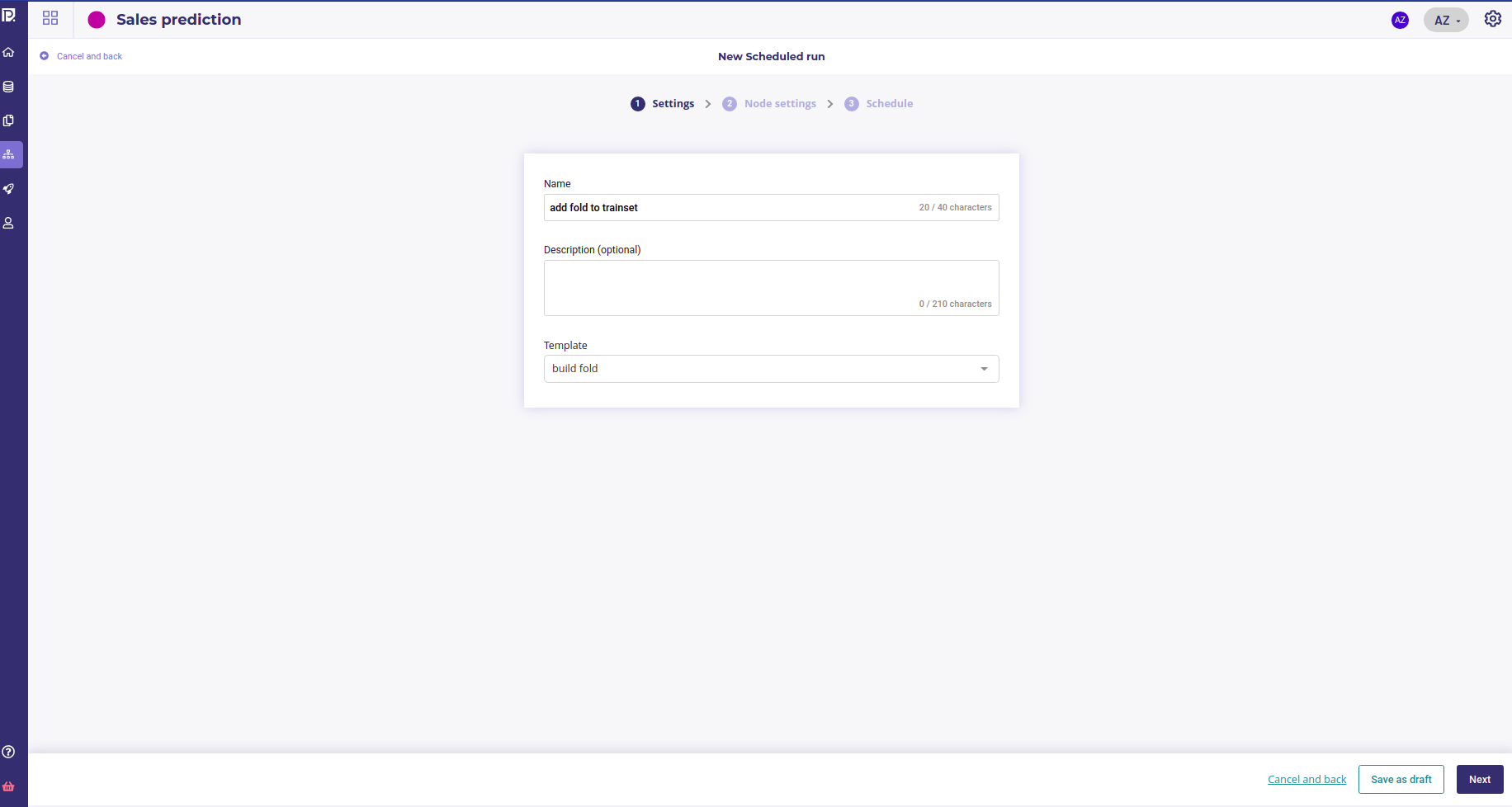
Create a new scheduled run
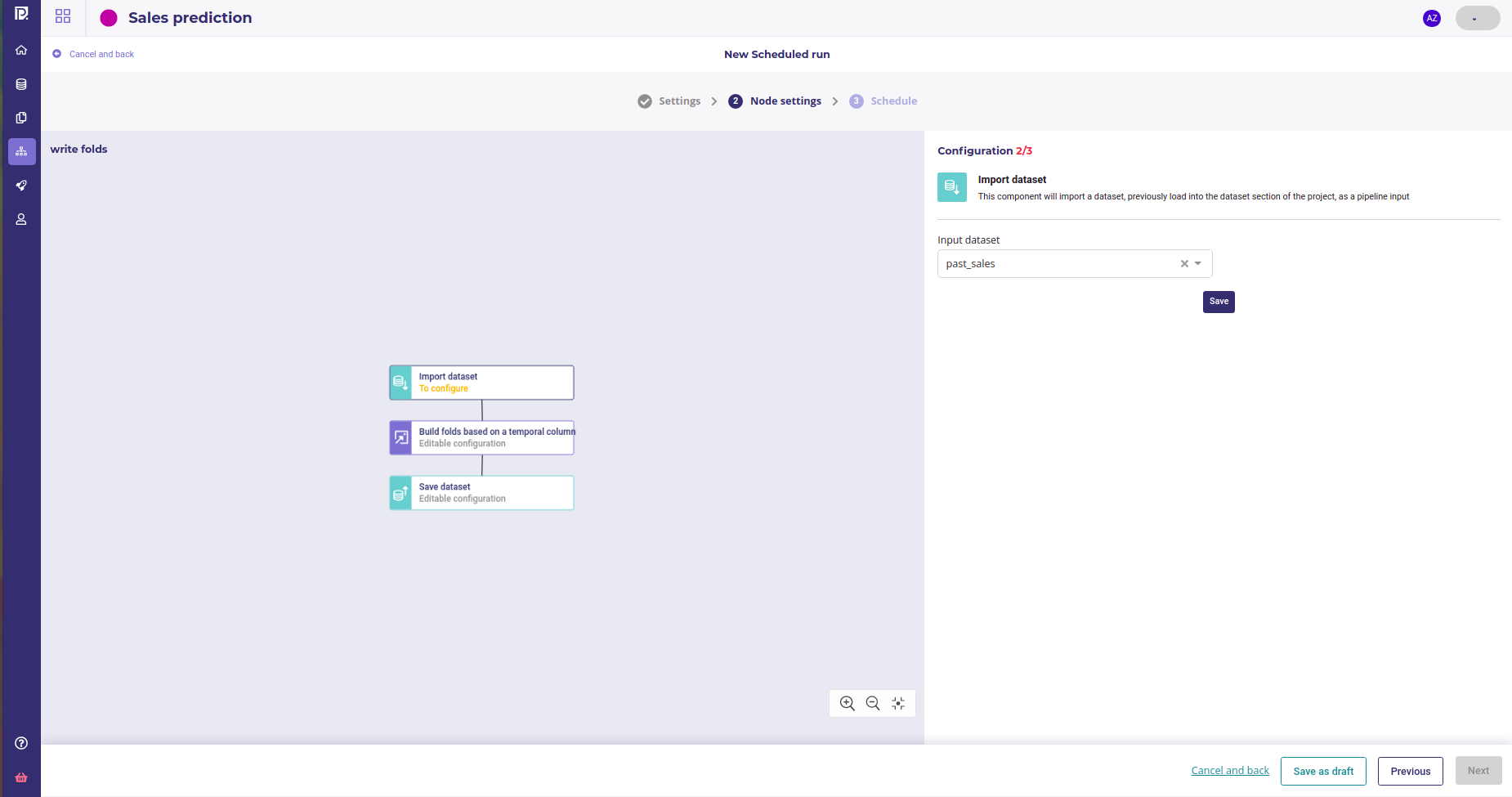
Set your trainset as the input dataset
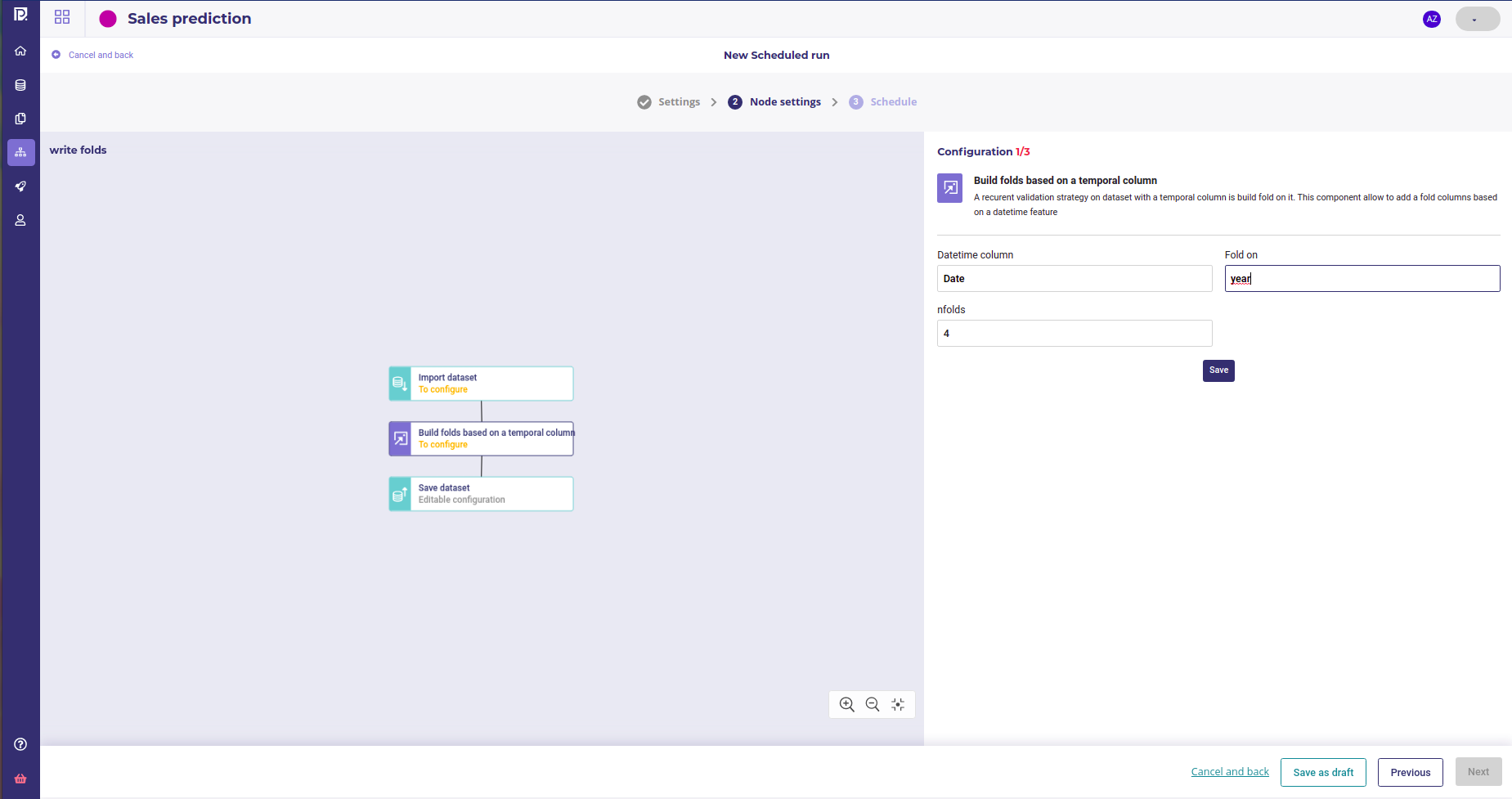
configure your fold component parameters
Once you did the configuration, select « Manual » as the trigger and run your Schedule run. In a few seconds, a new dataset should be available in your data section as a pipeline output with a new fold column
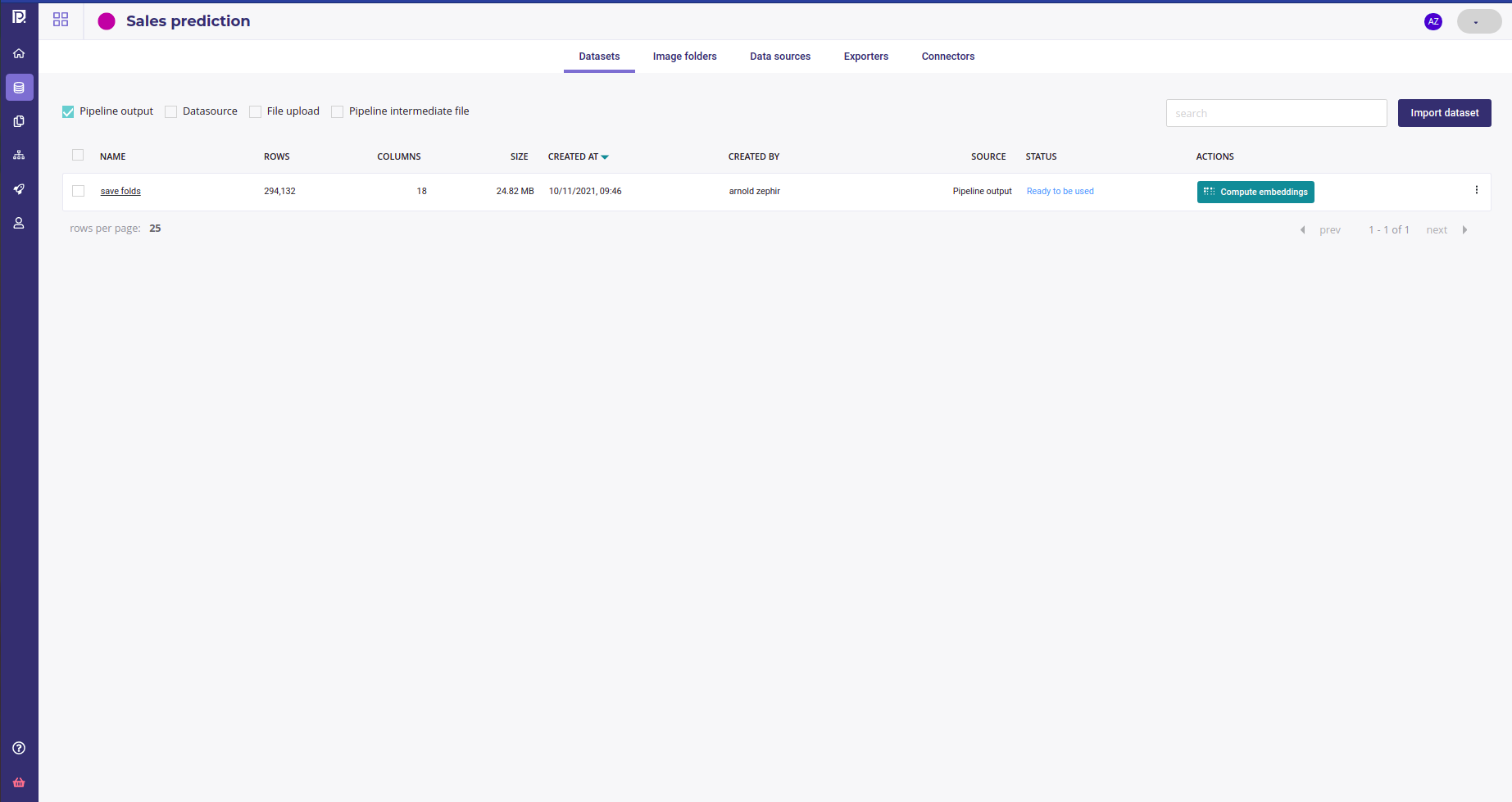
Pipeline output dataset
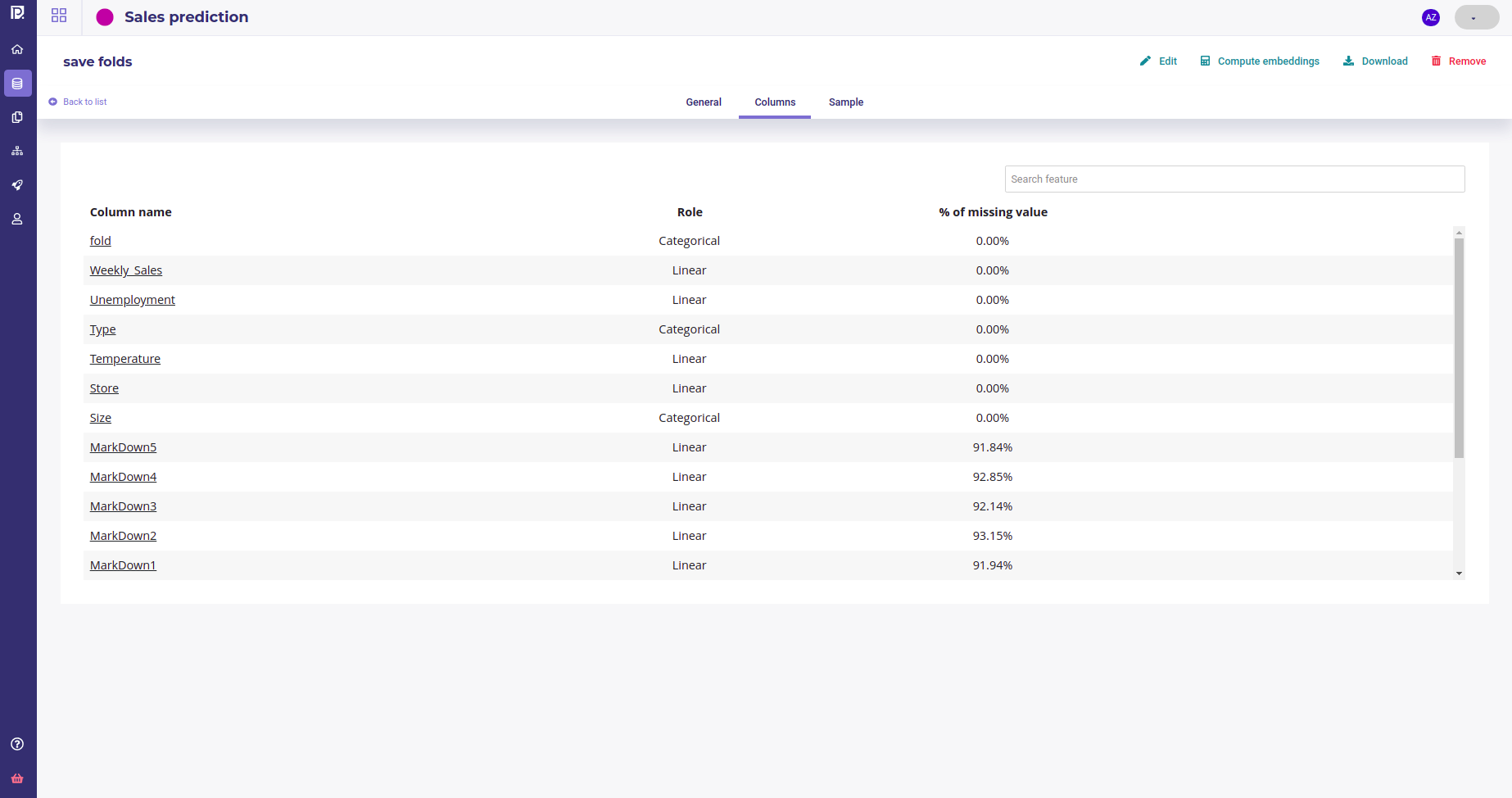
Pipeline output dataset
You now got a dataset with features for training model and an holdout to validate your models.
| Task | Status | Output | Time spent |
|---|---|---|---|
| Data acquisition | Done | one trainset, one holdout | 5mn |
| Feature engineering | Done | one engineered dataset with features, one holdout | 20mn |
Build your own¶
For the sake of this guide, we built a very basic feature engineering pipeline but you can add as many transformation as you want and build very complex pipeline.
Here we only have one component that adds a fold column, which is the year modulo 4. You can make the feature engineering on your local machine with the following code. Yet, if you want to build your own component you can follow this guide or some others
1 2 3 4 5 6 7 8 9 10 11 12 13 14 | def addfold(df: pd.DataFrame, dtcol: str="dt", foldon:str="year", nfolds:int=3) -> pd.DataFrame:
if nfolds <=0 :
nfolds=3
df[dtcol] = pd.to_datetime(df[dtcol])
df["fold"] = df[dtcol].dt.month % nfolds
if foldon=="year" :
df["fold"] = df[dtcol].dt.year % nfolds
if foldon=="day" :
df["fold"] = df[dtcol].dt.day % nfolds
if foldon=="hour" :
df["fold"] = df[dtcol].dt.hour % nfolds
return df
|
Define the problem¶
This is the most important part and the one that should be allocated the most time.
In this step, you’re going to define with the Line of business how to qualify the project as a success and you, as a datascientist, are gonna to translate this as datascience metrics.
Regression metrics
Choosing the best metrics is out of the scope of this document but you must spend time with your business teams and ask this kind of question :
- Imagine that I have the perfect model, does it make me gain something ?
- how many money do I lost if I forecast 110 sales instead of 100 ?
- how many money do I lost if I forecast 90 sales instead of 100 ?
- are all the predicted product equal ?
- Should I forecast the total number of item sold, the total amount of sales (in € ), the total weight of my items or the total volume ?
- How much time before should I forecast ?
- etc …
As a datascientist, by using an AutoML platform, your role is not to code in python or make dockerfile but to transcribe business problems to Machine Learning parameters.
However, in Prevision Platform, your can build what is called experiment to help refine your objectives
| Task | Status | Output | Time spent |
|---|---|---|---|
| Data acquisition | Done | one trainset, one holdout | 5mn |
| Feature engineering | Done | one engineered dataset with features, one holdout | 20mn |
| Define the problem | Done | a metric to validate the models | A week |
Experiment¶
An experiment is a set of Model Building with slighty different parameters accross version and a common Target on each version. On each experiment, many models will be automatically built evaluated in cross-validation and on the holdout dataset if you provide some.
In our case, the models will be trained on our engineered dataset with a fold column and evaluated on an holdout provided by IT Team.
It is very important to have a good validation stategy to guarantee that the model built in the experiment phase will stay stable on production. Here we choose to :
- build a fold column on the modulo of the year number so that we stay confident that the model learned some trends that stay stable over the year
- Validate on an holdout with sales from a year that was not in the trainset
Hence, if the holdout score is near to the cross validation score, we know that our model is going to stay good when launched in production and shared accros the company
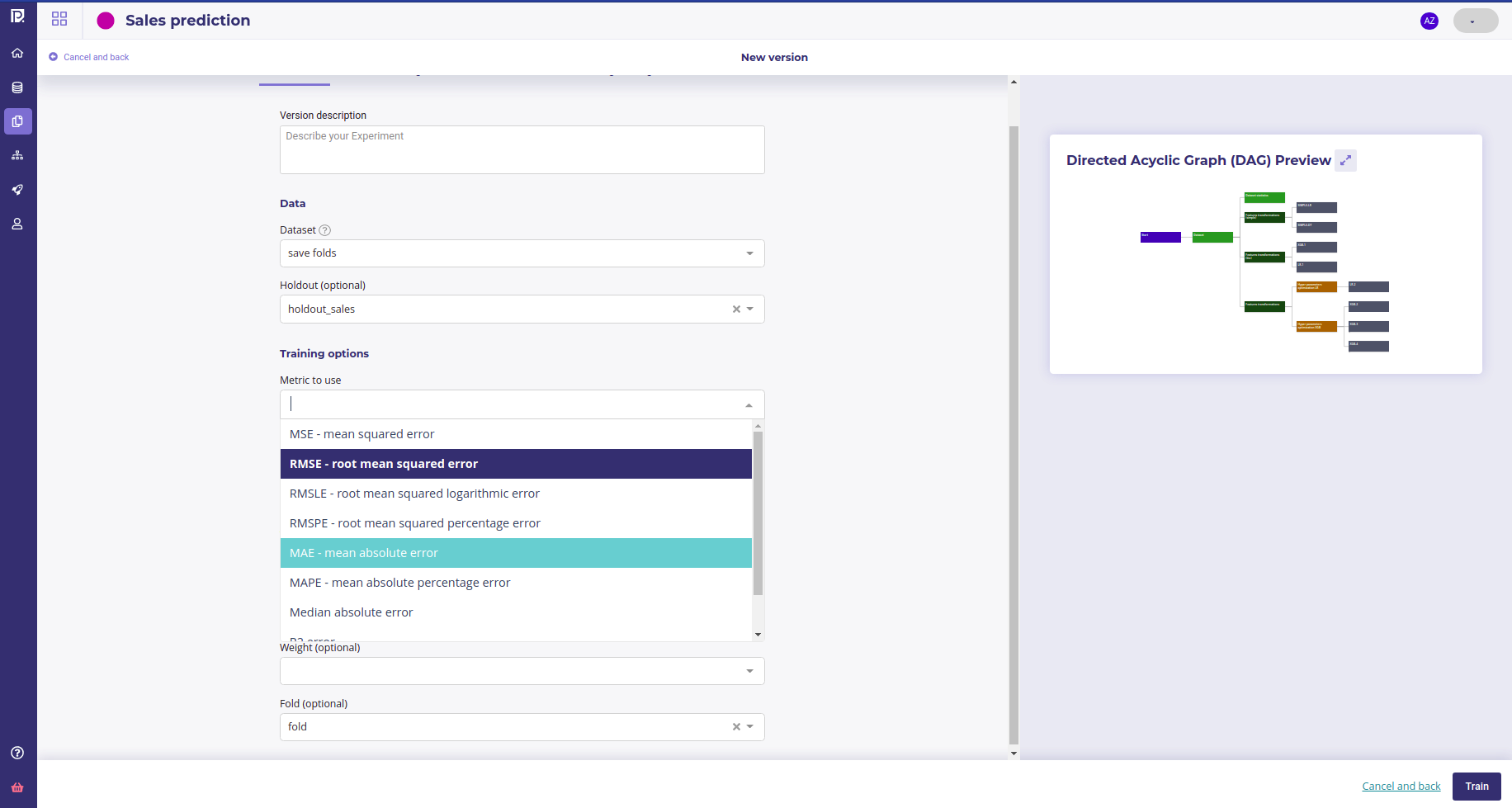
For creating a new experiment, go to the experiments section of your project and click new experiment. You could choose to import some external models if you have some but here we are using the AutoML Prevision Engine. As we want to forecast sales, choose « Tabular » and « Regression ». Give a name to your experiment and click « Create experiment »
Setting the experiment up
When you create a new experiment, there is no version of the experiment existing so you will be prompted to create a new version. The next screen is where you setup all your experiment parameters :
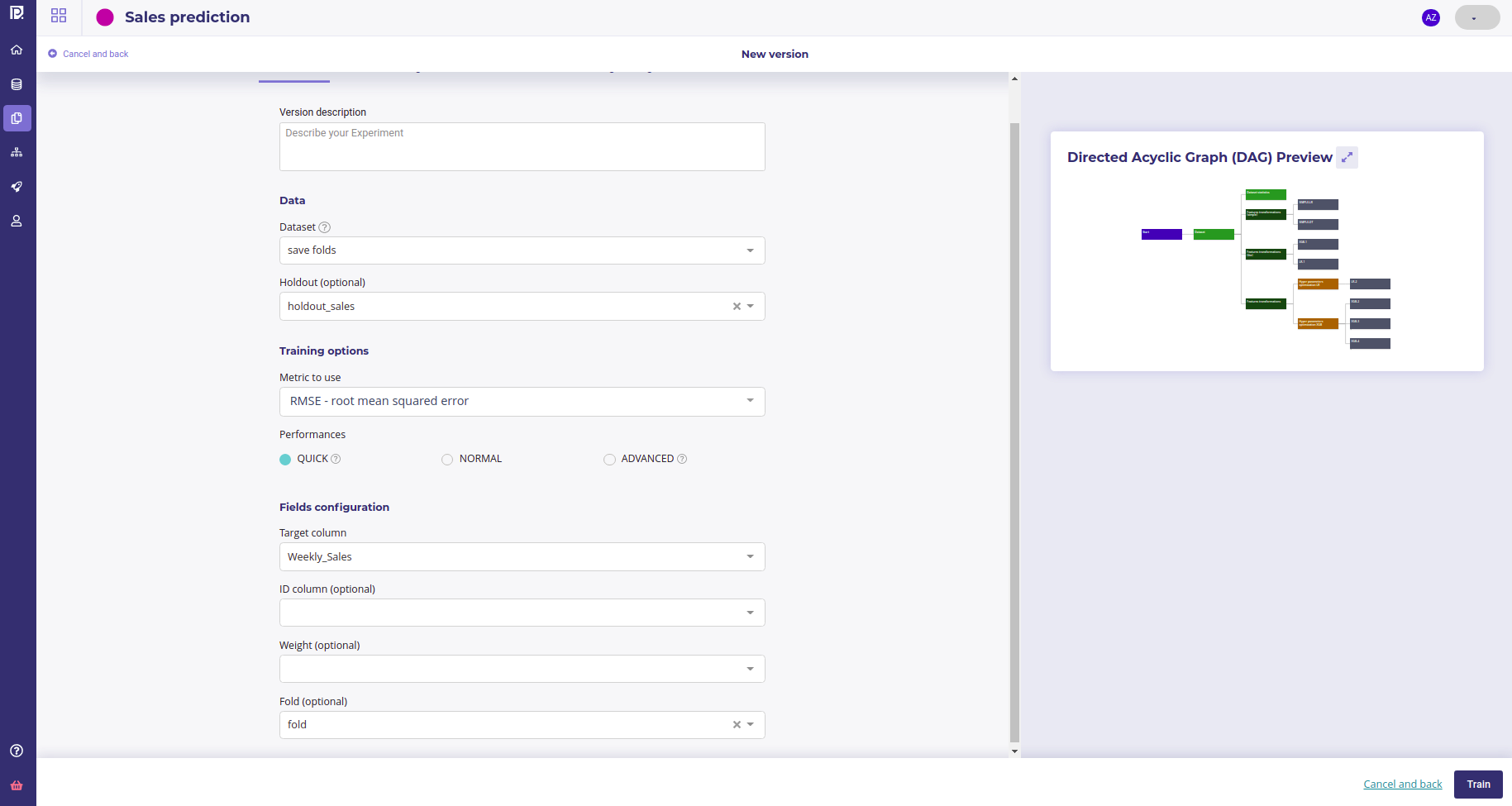
Experiment parameters
- The train dataset : use the output of the Schedule run from the step 2 with engineered features
- The holdout dataset : use a dataset with same target thant trainset but with data that are not in the trainset
- The metric : use the fittest metrics that solves the business objectives defined in the step 3. You can change it on each version of your experiment so run as much version as you need if you are not sure
- set your target ( here we choose « Weekly Sales » )
- and set the fold column up, using the column built during the feature engineering phase.
Note that you may go the models and feature engineering tabs to change some automl configuration but in most of case the default configuration is fine.
Once done, click on train to launch the training. The platform will immediately start to build and select models with the best hyper parameters. The models will stacks in the « models » tabs of your experiment :
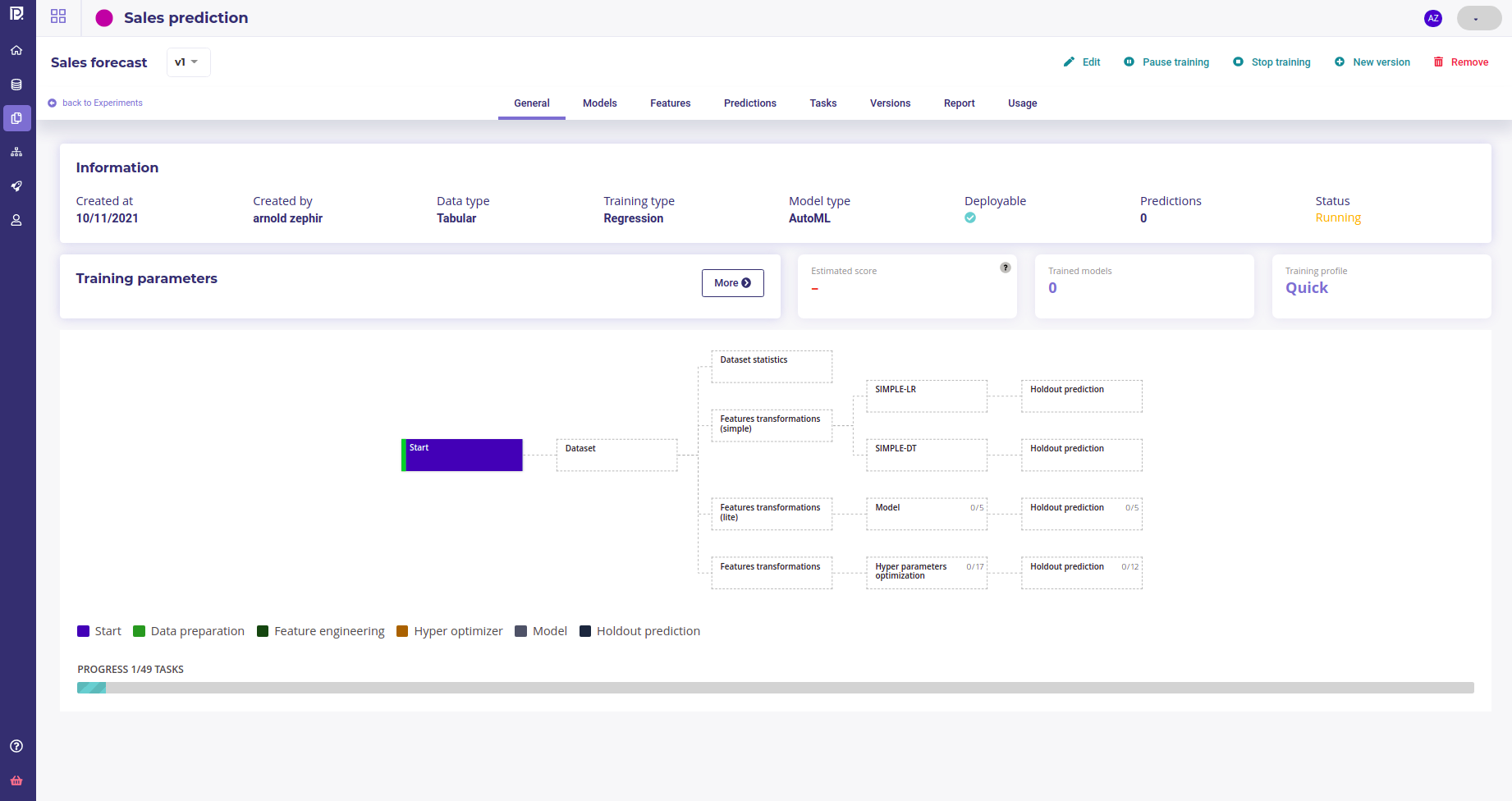
The experiment dashboard
Note that you can launch another version of your experiment as soon as you want, for testing other metrics for example, by using the new version button in the top right corner.
If you have several version , the experiment dashboard will always display the last version but you can change to another version with the version dropdown menu or the versions list tabs
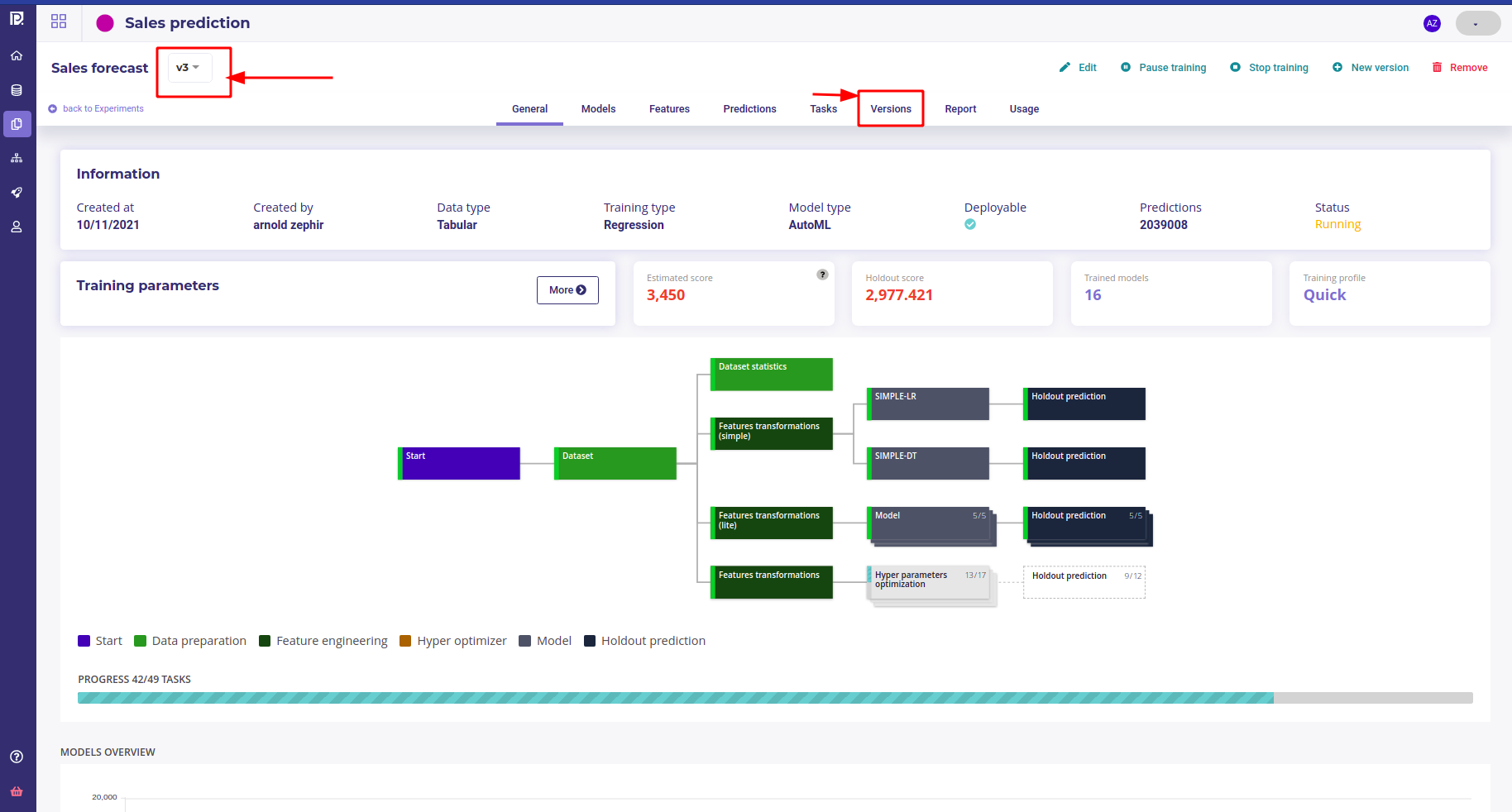
The experiment dashboard
You can launch as much version as you want and they will run in parallel. You can now grab a coffee and wait till models are built ! Depending on the size of your dataset and the plan you subscribed, expect to wait from 10mn to 2 hours before having enough models to evaluate your experiment. In our case, we got our model in ~20mn
| Task | Status | Output | Time spent |
|---|---|---|---|
| Data acquisition | Done | one trainset, one holdout | 5mn |
| Feature engineering | Done | one engineered dataset with features, one holdout | 20mn |
| Define the problem | Done | a metric to validate the models | A week |
| Experiment | Done | ~100 models | ~20mn |
Evaluate¶
After a few minutes, you should have between 15 and 40 models for each version, depending on your option
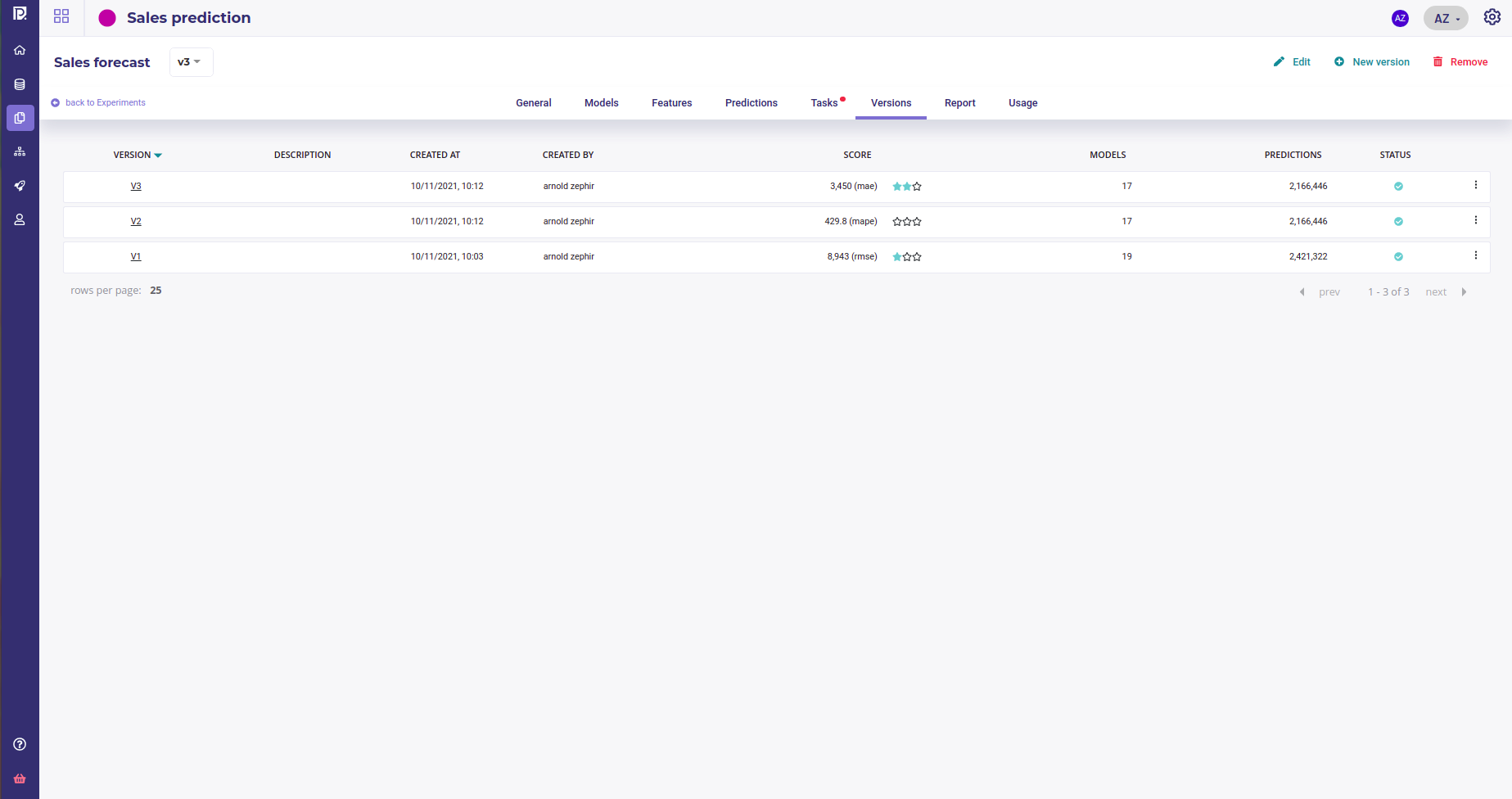
List of experiment versions.
This step is all about evaluating all the models produced and select 2 to 4 models to deploy for testing model in real conditions.
First, have a quick look at the list of versions below ( tab versions of your experiment ). There is a small 3-star evaluation that gives you informations about versions quality. In that case, the Version 3, that has been trained on Mean Absolute Error, looks the most promising. Click on the version to enter the version dashboard for deepest analysis.
On the Version dashboard, you got several indicator but the most important is the models comparator :
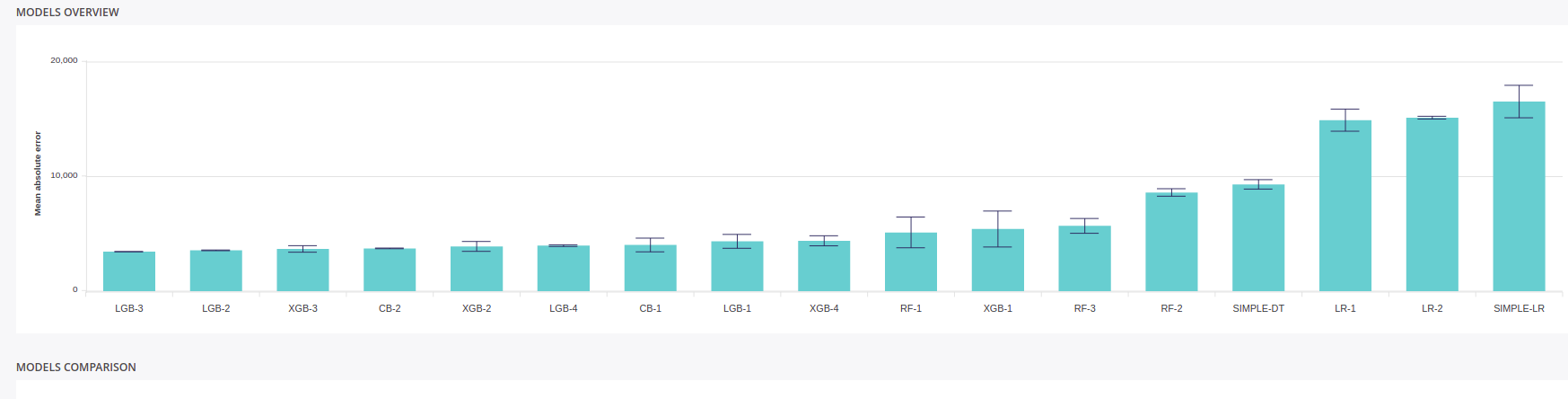
List of models of a version
You can quickly see :
- performance of each model done , evaluated on the metrics you choose for this version.
- stability of each model ( represented with a small error bar ) computed on a cross validation of the trainset using the fold column provided
Dumb models
Prevision Platform always produces what we sometimes call « dumbs models », a linear regression and a Random Forest of only 5 depth, called simple-LR and simple DT. It is always a good idea to watch performance of this models against the most complexe one and ask yourself if using them could be good enough for your problem.
Indeed, as they are very simple :
- they can be implement in sql ( auto-generated code is even provided on the model analysis page )
- they often are more explainable and are more accepted from the Business teams, are they are easier to understand and use.
As a datascientist, accepting to use a simple if-else instead of complex Blend of Gradient Boosting if it solves the issue is your responsibility too !
On the experiment above, the :
- LGB-3
- XGB-4
- CB-2
Looks promising so we are going to have a closer look. Click on the model barplot to enter the detailed model analysis, CB-2 for example.
Here you got more detail about the models you select, like various metrics and the actual vs predicted Scatterplot
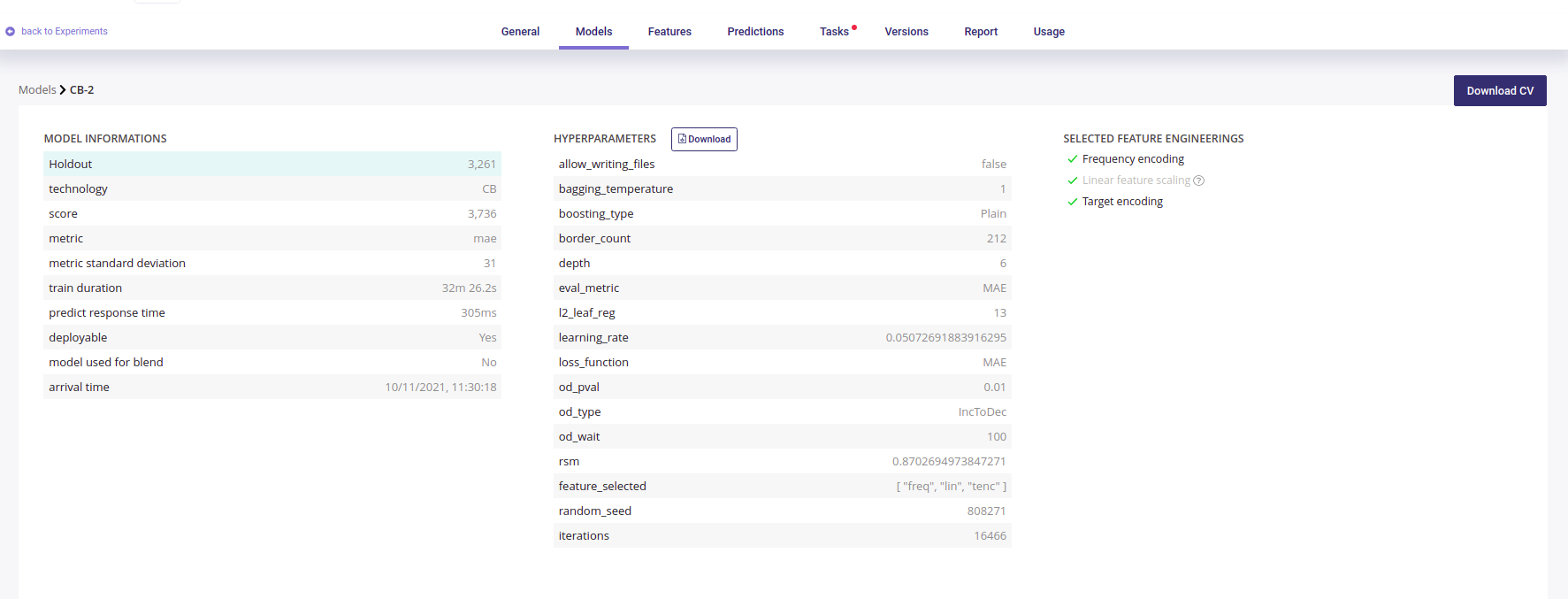
All the metrics of the model
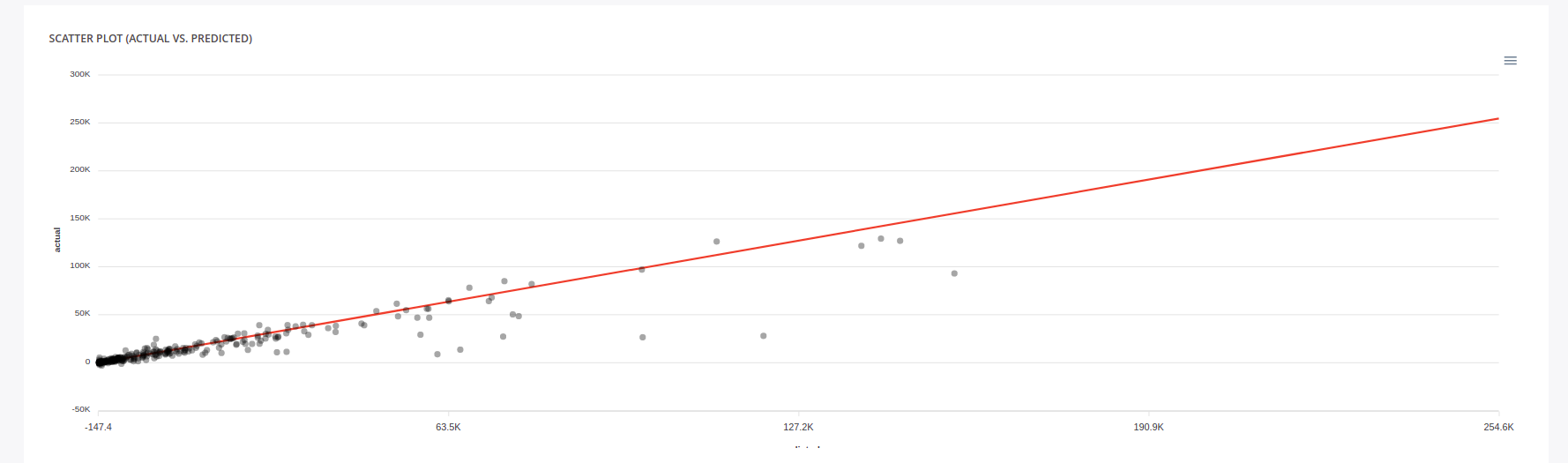
Predicted vs actual
You can download the Cross validation file if you want to run your own evaluation. The CB2 is quite good but if we look at the Scatterplot, we see that performance fall in the range from 40k to 80k. If we go to the LGB-3 page, we see a more stable performance
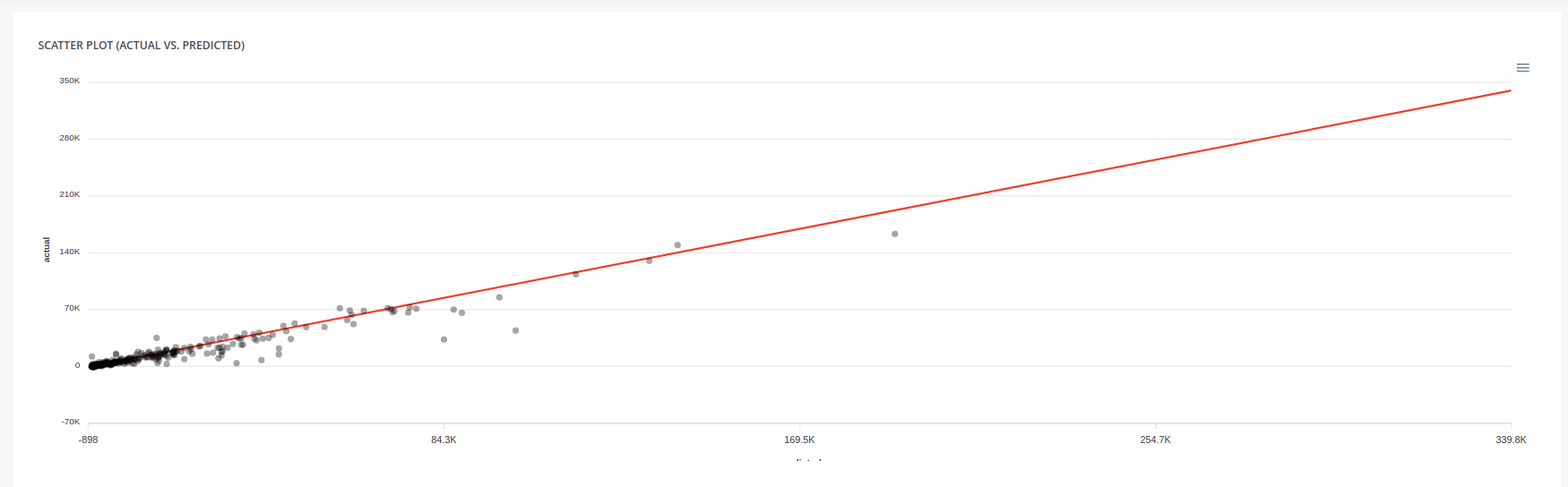
Predicted vs actual ( LGB-3 )
Evaluating a model is out of the scope of this guide but be aware that it is another step where you MUST involve your business team and explain each metrics and chart to them so you choose together the model that solves their problem the best.
The model analysis page is full of metrics to parse andyou can run as much experiment as you want in order to find the model that fit the business probleme the best.
After discussions with the LoB , we decided to keep the LGB-3 and the XGB-4, one because it performs well and the others because its performance are stable when evaluated on the holdout.
In order to refine this, we are now going to deploy both models and see how they perform in real world.
| Task | Status | Output | Time spent |
|---|---|---|---|
| Data acquisition | Done | one trainset, one holdout | 5mn |
| Feature engineering | Done | one engineered dataset with features, one holdout | 20mn |
| Define the problem | Done | a metric to validate the models | A week |
| Experiment | Done | ~100 models | ~20mn |
| Evaluate | Done | 2 models selected with business team | A week |
Deploy¶
In this step two models will be deployed in order to test them on real data and usage. While deployed, their performance will be closely monitored for deciding if they are good for production grade utilisation.
Go to the « Deployment » section of your project and click on deploy a new experiment. Select LGB-3 as main model and XGB-4 as a challenger in order to see which one performs best on real data.
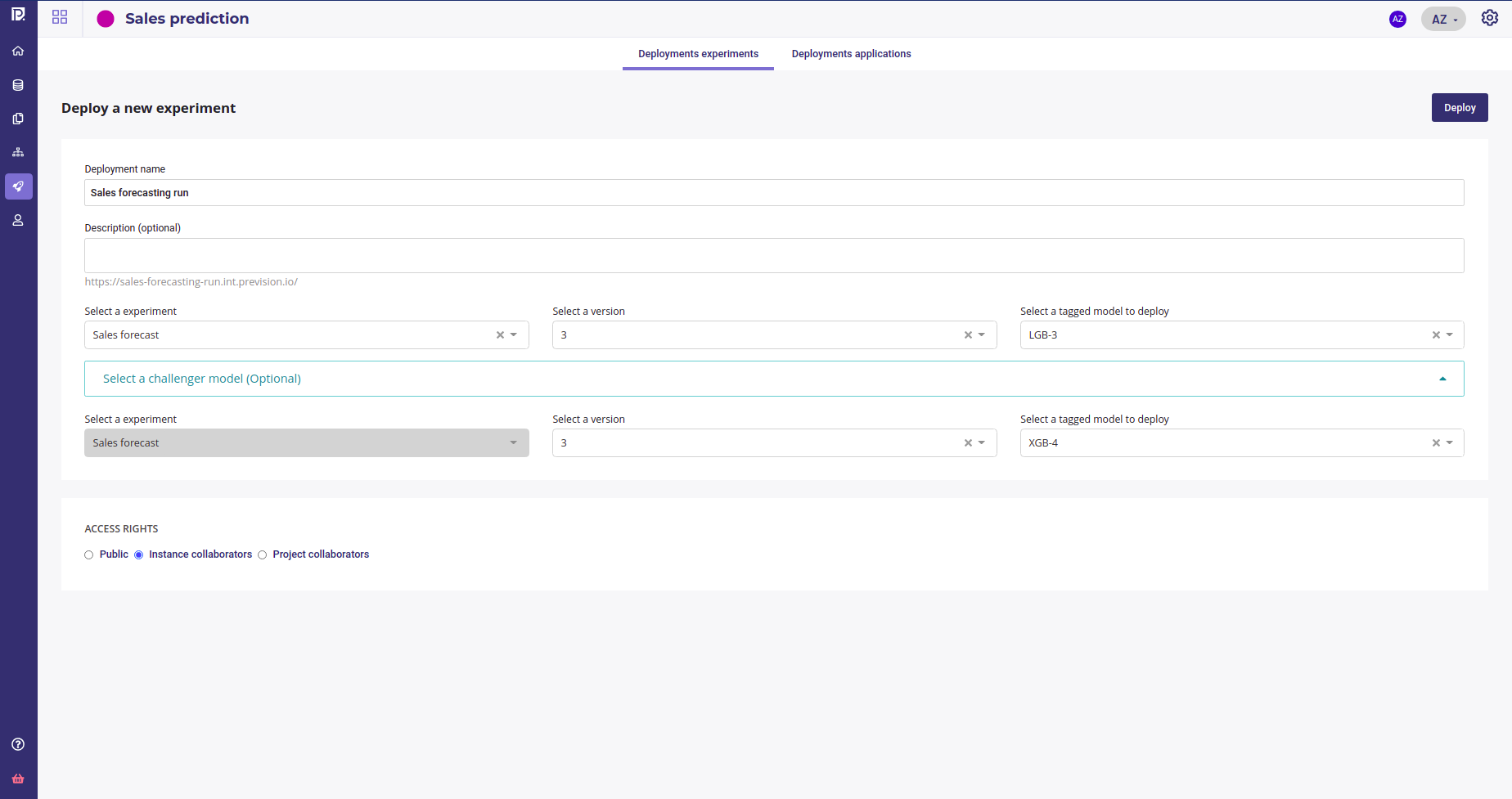
Set your main and challenger
The Main model will be used for prediction but each time you call it, a prediction will be done with the challenger model too and chart ill be generated so you can compare them.
Wait a few minutes to get :
- a standalone webapp for human user to test ( « Application link » url )
- a batch predictor available for scheduling prediction
- a REST API for calling the model from others software ( « Documentation API » link )
Set your main and challenger
That’s all. Your model can now be called from any client of your company and all its requests will be logged for further monitoring. Yet, in order to send prediction each week to the sales team, you need to schedule them.
| Task | Status | Output | Time spent |
|---|---|---|---|
| Data acquisition | Done | one trainset, one holdout | 5mn |
| Feature engineering | Done | one engineered dataset with features, one holdout | 20mn |
| Define the problem | Done | a metric to validate the models | A week |
| Experiment | Done | ~100 models | ~20mn |
| Evaluate | Done | 2 models selected with busines team | A week |
| Deploy | Done | Model available accross the organisation | 5mn |
Schedule¶
Once any model is deployed, it can be used to schedule prediction. First step is to insert it into a pipeline template and then create a new Schedule using this template.
Note that you need helps from your IT team in this step, in order to define the name of the table where you will read the features from each week. You can use the same table that will be overwritten each week, for example « sales to predict » to read and « Sales predicted » to write, or a more complexe naming scheme.
First you need two create two new assets :
- a new datasource that gonna link to the Table were the IT team is going to put the features for prediction each week
- a new exporter to push the result
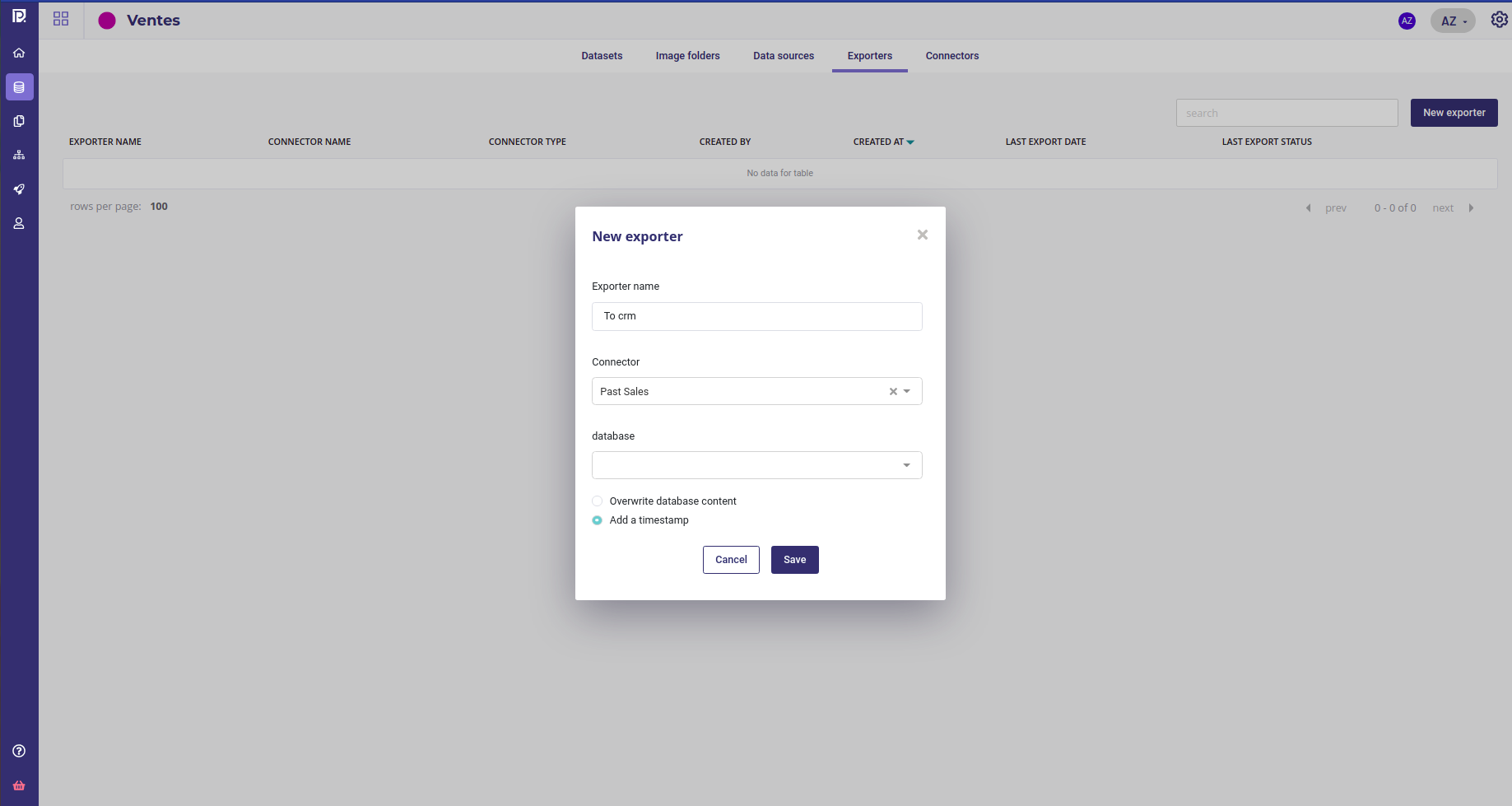
Create an exporter to push data to your crm
So you can use them in a new pipeline template with 3 nodes again :
- Import from the datasource, where the datasource is the table with all the weekly features
- a deployment predict regression node
- an export dataset node, that use the exporter above
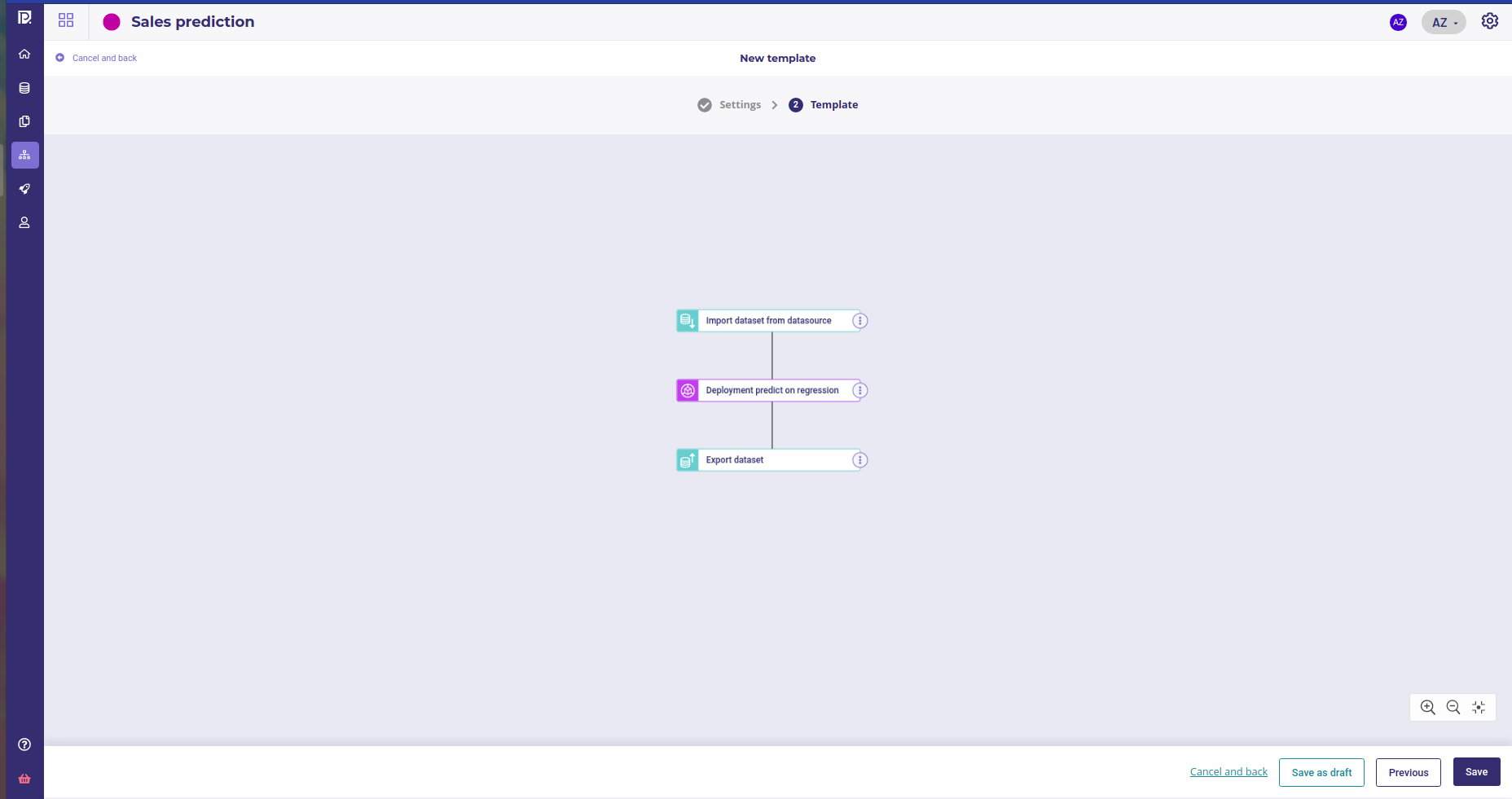
Template
Once you got your template, create a new Schedule based on it
Use your template in a schedule run
And choose the Name of your deployment as the experiment deployment Id
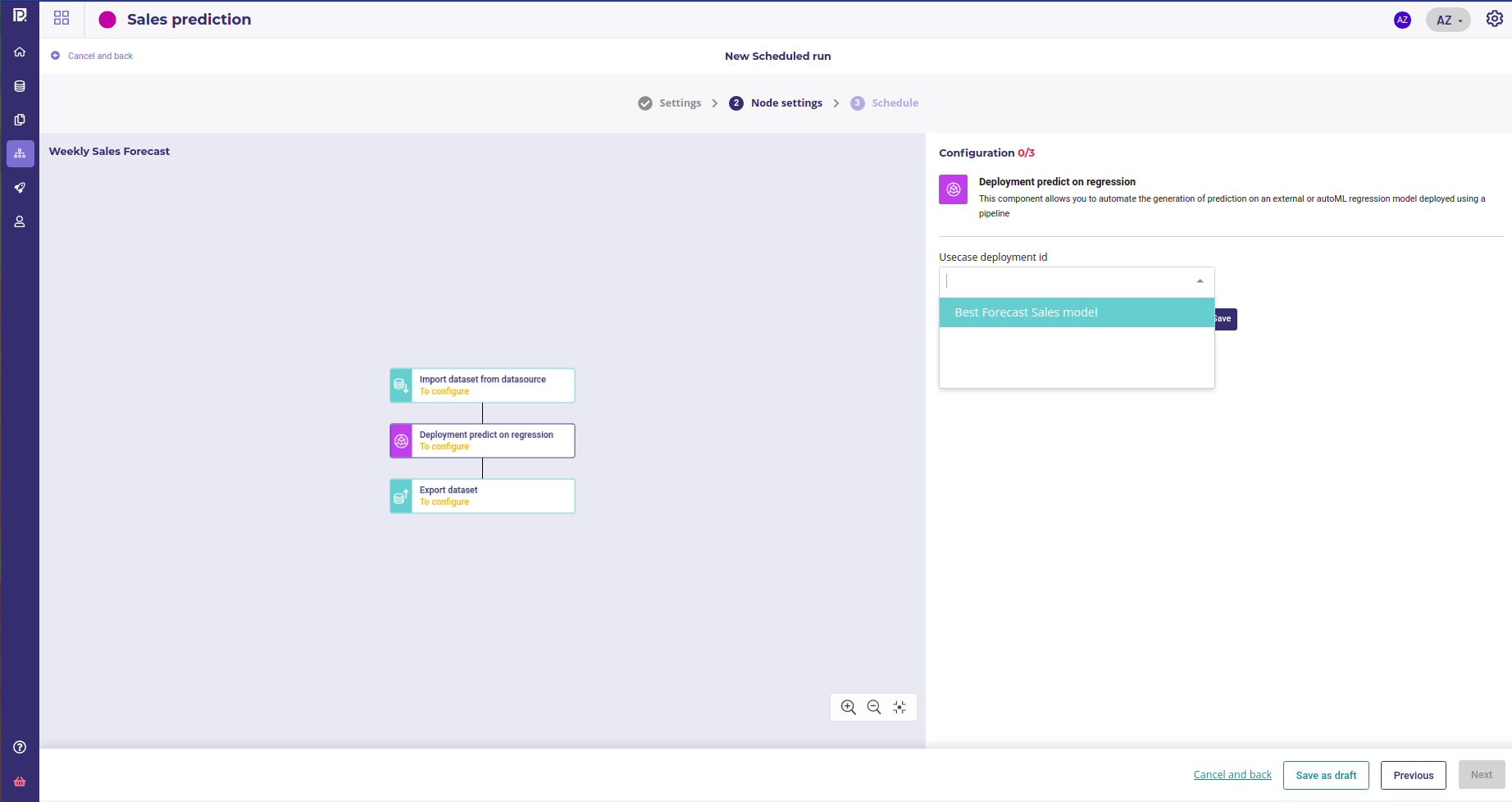
Use your template in a schedule run
And then, instead of the manual Trigger, use a periodic one , putting the configuration that fits your need the best ( here, a weekly prediction each Monday at 7:00 AM )
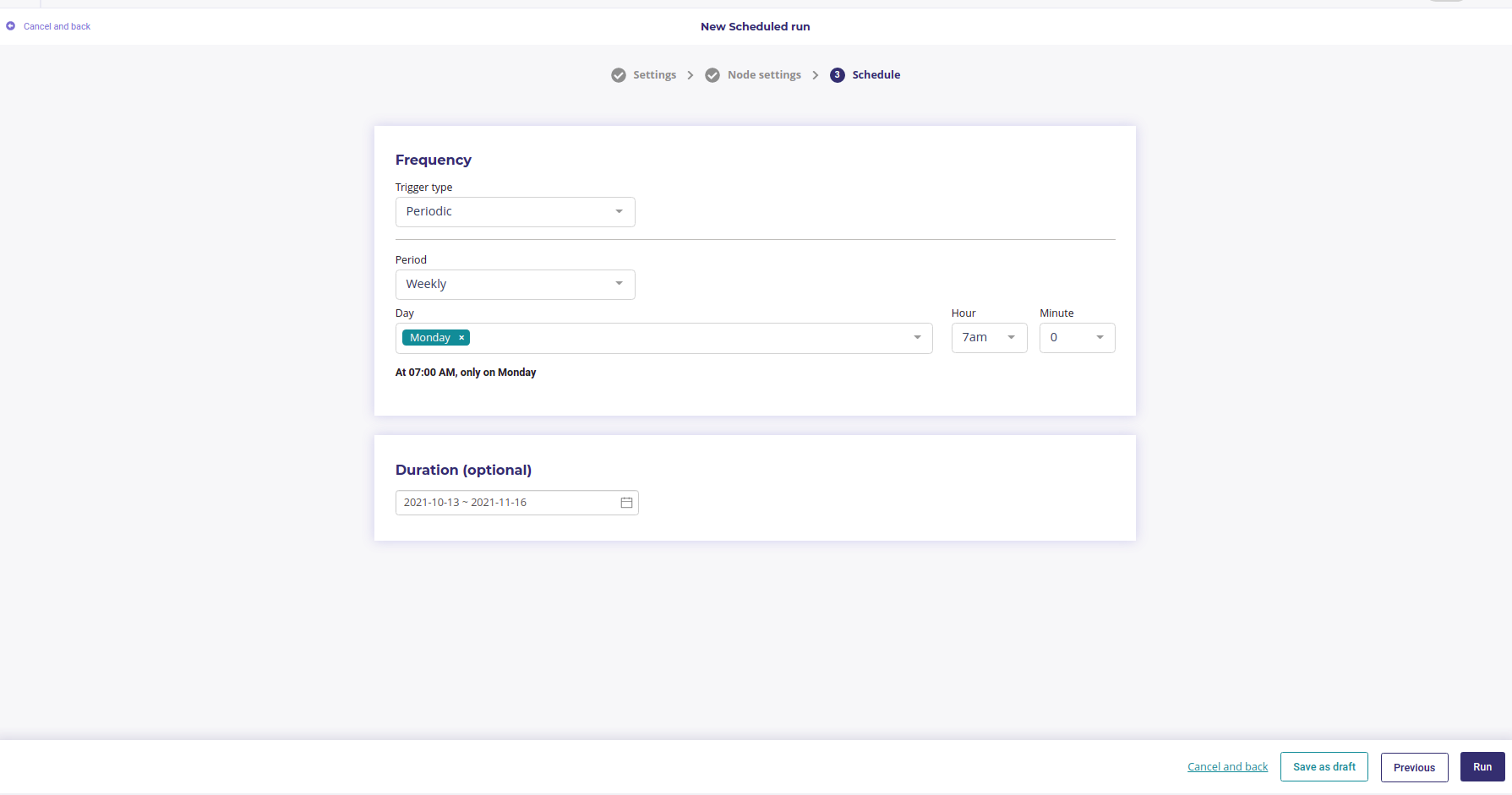
Scheduling a prediction each monday Morning
Click run and wait few seconds. Your Prediction is now scheduled to run every Monday , from the table of « sales to predict » to the « Sales predicted » table of your databases.
| Task | Status | Output | Time spent |
|---|---|---|---|
| Data acquisition | Done | one trainset, one holdout | 5mn |
| Feature engineering | Done | one engineered dataset with features, one holdout | 20mn |
| Define the problem | Done | a metric to validate the models | A week |
| Experiment | Done | ~100 models | ~20mn |
| Evaluate | Done | 2 models selected with busines team | A week |
| Deploy | Done | Model available accross the organisation | 5mn |
| Schedule | Done | Prediction in CRM each Monday at 09:00 | 20mn |
Monitoring¶
Once a model is deployed, each call to it will be logged, being unit one or scheduled batch. You can track your model into the Deployments section of your project by clicking on a deployed experiment name in the list of experiments to access the deployment dashboard :
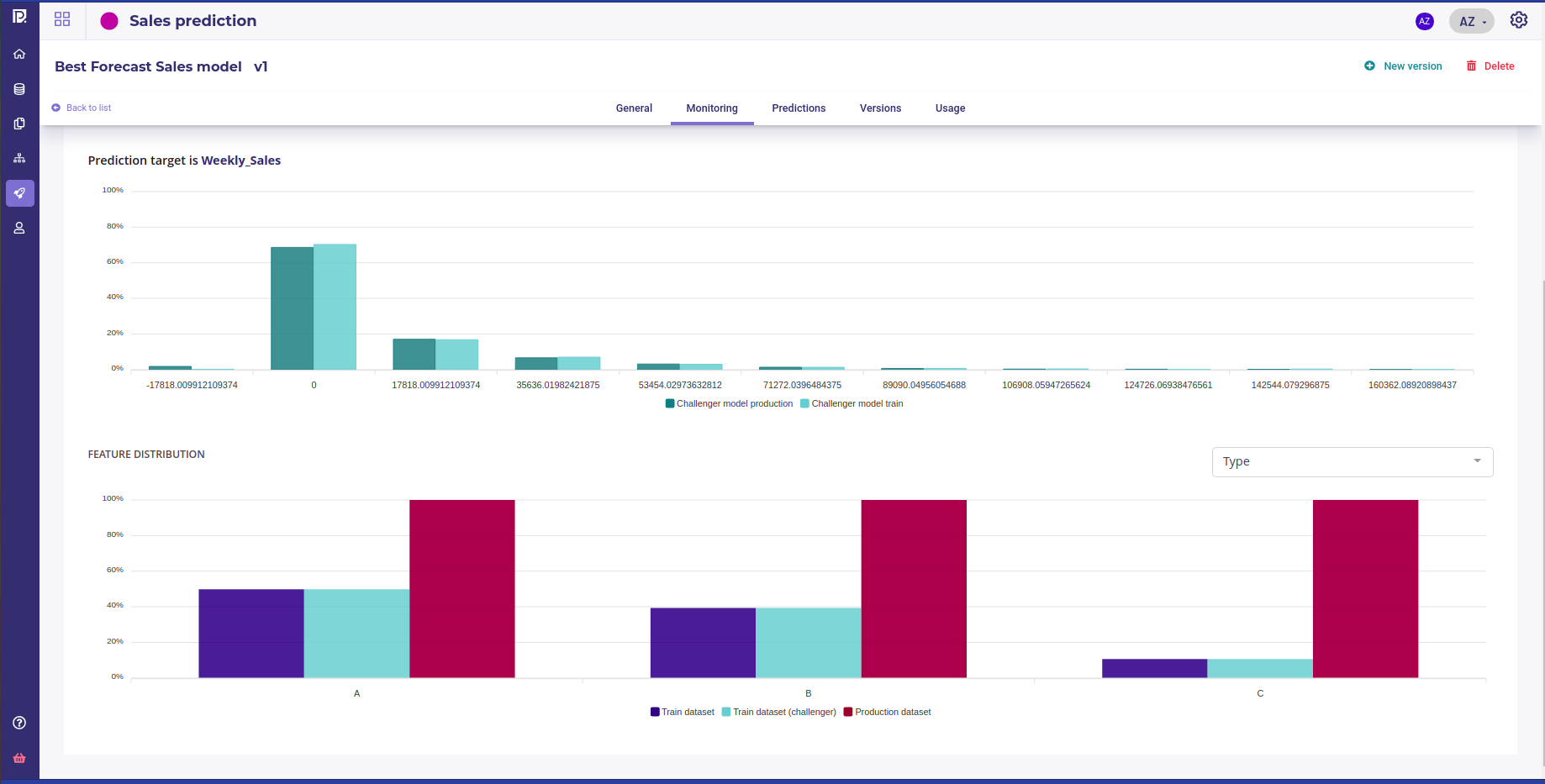
Train and production distribution
You can watch the features distribution of the trainset compared to the feature distribution seen in production and check the drift. Target distribution of the Main Model and Challenger model are shown side-by-side with those of the production in order to evaluate performance in a real application.
Under the monitoring/usage tab sit some SLA statistics about number of call average response time and errors.
By tracking all this indicators for a month or more, you can evaluate how does your model lives in production and check that it behaves the way you expected while evaluating it in the experiment step.
| Task | Status | Output | Time spent |
|---|---|---|---|
| Data acquisition | Done | one trainset, one holdout | 5mn |
| Feature engineering | Done | one engineered dataset with features, one holdout | 20mn |
| Define the problem | Done | a metric to validate the models | A week |
| Experiment | Done | ~100 models | ~20mn |
| Evaluate | Done | 2 models selected with busines team | A week |
| Deploy | Done | Model available accross the organisation | 5mn |
| Schedule | Done | Prediction in CRM each Monday at 09:00 | 20mn |
| Monitor | Done | Prediction in CRM each Monday at 09:00 | A month |
Conclusion¶
In this guide, you saw how to complete the whole datascience process in less than a morning and went from data to fully deployed model, shared accross the company with full monitoring.
Using a tool to solve the technical issue of the datascience, like finding the best model, deploy a model or import the data, allow to spend more time on what trully matters : talk with the Line of Business team to translate their problem to datascience configuration and metrics.