Computer Vision Model¶
In the prevision.io platform, you can train models using images for :
- regression
- classification ( either simple one with 2 class or multiclassification with more than 2 class )
And a Special one :
- image detection
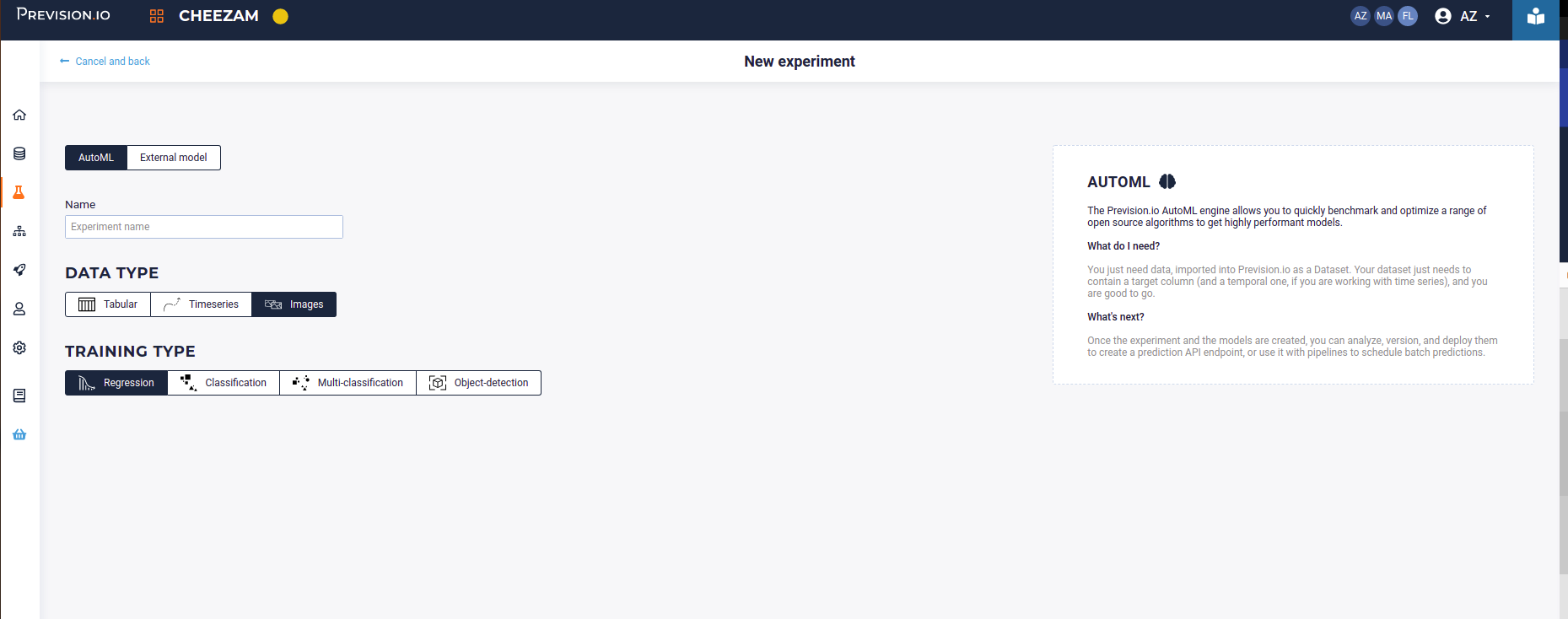
When selecting an image usecase, you can train a classification, a multiclassification, a regression or an object detector
Note that your models can be trained on mixed dataset : you can have a dataset with tabular datas, columns of text, categorical datas and linear one.
For example, this dataset is valid :
| id | path_image | description | screenshot_day | nbclick | cat | TARGET |
|---|---|---|---|---|---|---|
| 1 | games/action/screenshot_1.png |
|
2020-03-12 | 4555 | ACTION | offensive |
| 2 | games/action/screenshot_2.png | players compete […] | 2020-05-12 | 12298 | ACTION | neutral |
| 3 | games/simulation/screenshot_1.png | An intern in an […] | 2020-06-04 | 10024 | SIMULATION | offensive |
Setup¶
When training an image use case, you always need 2 assets :
- a csv dataset with path to the images and differents info ( and the target )
- a zip of images uploaded in your image folder storage space
The csv dataset is a classic dataset imported with connectors or uploaded via interface while the zip is a zip file of image set up on your local environment and uploaded to your image folder storage.
More over, for Object Detector traning, you need to draw bounding box onto your image and export them to Pascal Voc format.
Regression¶
A regression on images is a model that predict a number from an image, for example number of click from a thumbnail or a screenshot.
Classification¶
A classification is a model that predict class of an image. There could be 2 class or more. For example « smiling », « crying » or « thinking » from the image of a face.
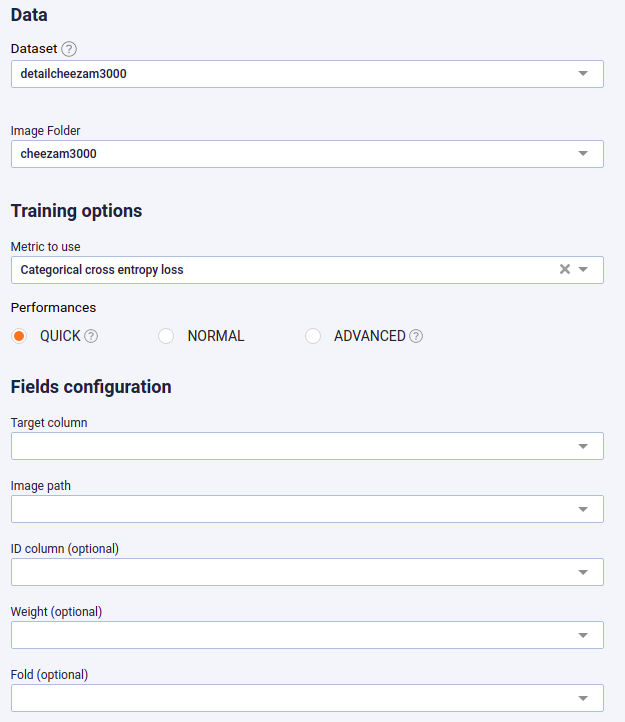
A classification use case with Image path input
Object detection¶
An object-detection use case is a model that from an image return zero, one or more bounding box with label.

An image with its training bounding box ( blue ), the predicted bounding box ( orange ) with predicted label and probability
Image Path¶
When there are image in a dataset, the path to each image from the root of the image folder should be put in a column and this column muste then be selected as the « Image path » column.
For example if your folder of image has this architecture :
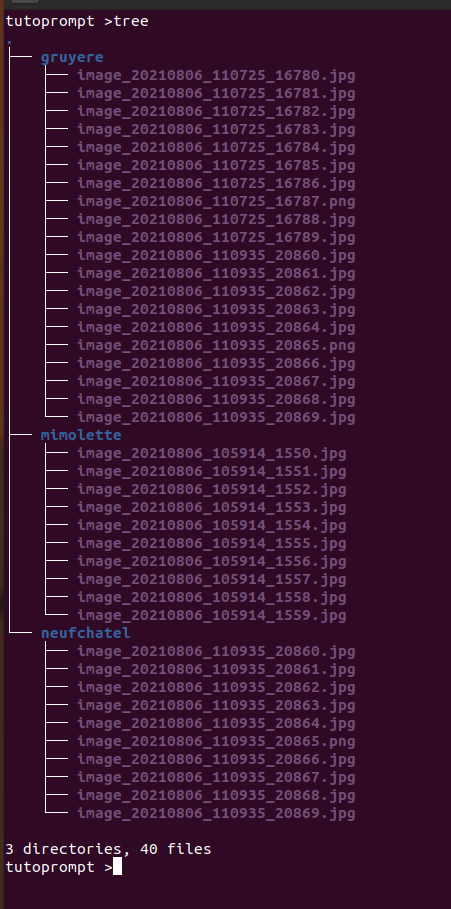
You should zip it from the root :
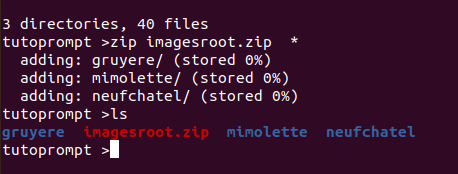
Upload the zip to your image folder Storage
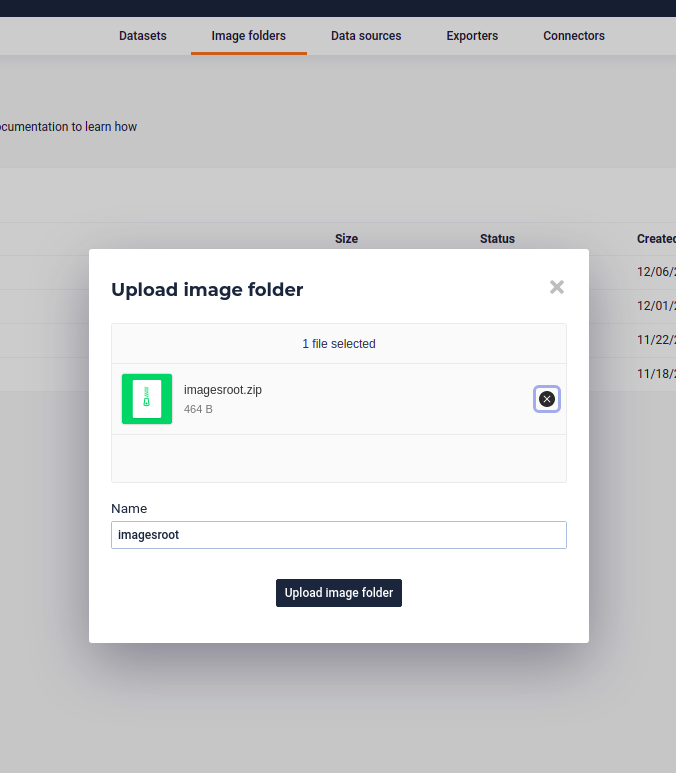
and your dataset should have a column with the following info
| path | class | otherinformation |
|---|---|---|
| gruyere/image_20210806_110725_16780.jpg | gruyere | yellow |
| gruyere/image_20210806_105914_1559.jpg | gruyere | yellow |
| mimolette/image_20210806_105914_1553.jpg | mimolette | orange |
| mimolette/image_20210806_105914_1558.jpg | mimolette | orange |
| mimolette/image_20210806_105914_1551.jpg | mimolette | orange |
| neufchatel/image_20210806_110935_20864.jpg | neufchatel | white |
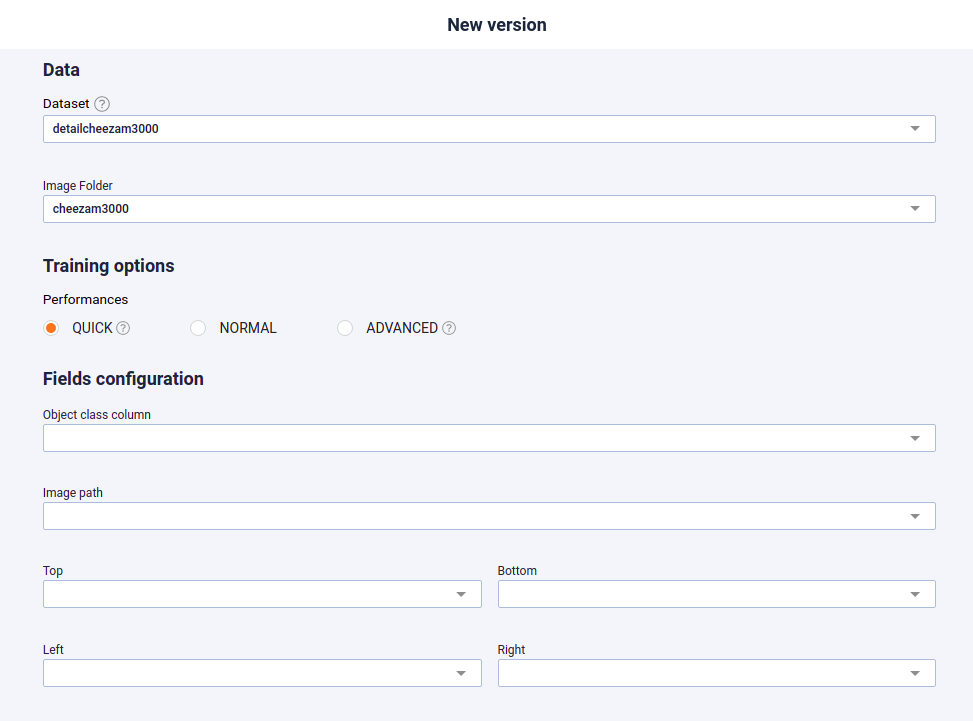
When setting the experiment, this path from the zip root should be mapped to the “image path” input.
Label or class¶
For classification, Multiclassification and Object Detection, you must set a column with the name of a class, or label
| path | label | otherinformation |
|---|---|---|
| gruyere/image_20210806_110725_16780.jpg | gruyere | yellow |
| gruyere/image_20210806_105914_1559.jpg | gruyere | yellow |
| mimolette/image_20210806_105914_1553.jpg | mimolette | orange |
| mimolette/image_20210806_105914_1558.jpg | mimolette | orange |
| mimolette/image_20210806_105914_1551.jpg | mimolette | orange |
| neufchatel/image_20210806_110935_20864.jpg | neufchatel | white |
You can call it anything you want but when setting your experiment, you need to select it in the “class” input selector
Bounding box¶
If you want to train a model to detect object on a image, you must run an Object Detection training and you must provide a dataset with bounding box for training
This bounding box is described in a dataset in csv format that can be imported or uploaded to your data section. Bounding box always use 4 columns to be described but there are two format for bounding box :
- Pascal Voc bounding box : x-top left, y-top left,x-bottom right, y-bottom right
- Yolov bounding box : x-top left, y-top left, width, height ( of the bounding box )
Prevision Platform use the Pascal Voc Bounding box format in csv. So to describe a bounding box , you must provide 4 more columns and map them in the input interface when setting your object detection experiment :
| path | category | xleft | ytop | xright | ybottom | imgname | labels |
|---|---|---|---|---|---|---|---|
| image_20210806_105845_425.jpg | patemolleacroutelavee | 228 | 634 | 846 | 984 | image_20210806_105845_425.jpg | vieuxboulogne |
| image_20210806_105845_428.jpg | patemolleacroutelavee | 83 | 99 | 302 | 329 | image_20210806_105845_428.jpg | vieuxboulogne |
| image_20210806_105845_434.jpg | patemolleacroutelavee | 0 | 4 | 188 | 145 | image_20210806_105845_434.jpg | vieuxboulogne |
| image_20210806_105846_446.jpg | patemolleacroutelavee | 36 | 8 | 244 | 215 | image_20210806_105846_446.jpg | vieuxboulogne |
Note that for object detection, there can be several object in one image. So your dataset may have many row with same image paht but different bounding box and label :
| path | xleft | ytop | xright | ybottom | labels |
|---|---|---|---|---|---|
| image_20210806_105845_425.jpg | 228 | 634 | 846 | 984 | vieuxboulogne |
| image_20210806_105845_425.jpg | 455 | 877 | 565 | 984 | mimolette |
| image_20210806_105845_425.jpg | 28 | 64 | 754 | 800 | mimolette |
| image_20210806_105845_425.jpg | 22 | 34 | 600 | 900 | cabecou |
Object Segmentation¶
Prevision.io does not provide Object Segmentation models.
Launch train¶
Once you had mapped each of the input to the corresponding columns, and given a name to your experiment, you can click on the train button and the training will start.
For Regression, Classification and multiclassification, you will find the standard metrics and chart. For Object Detection, the metrics is Mape and represent the accuracy of the bounding box.