Natural Language Processing¶
Text Similarity parameters
Even if considered as a training type for tabular data type, text similarity experiments are particular and need specific training options. Text similarity models allow to retreive textual documents from a query. For example, from « Red shoes for girls » query, your model should return a corresponding item.
Creating a Text similarity Model¶
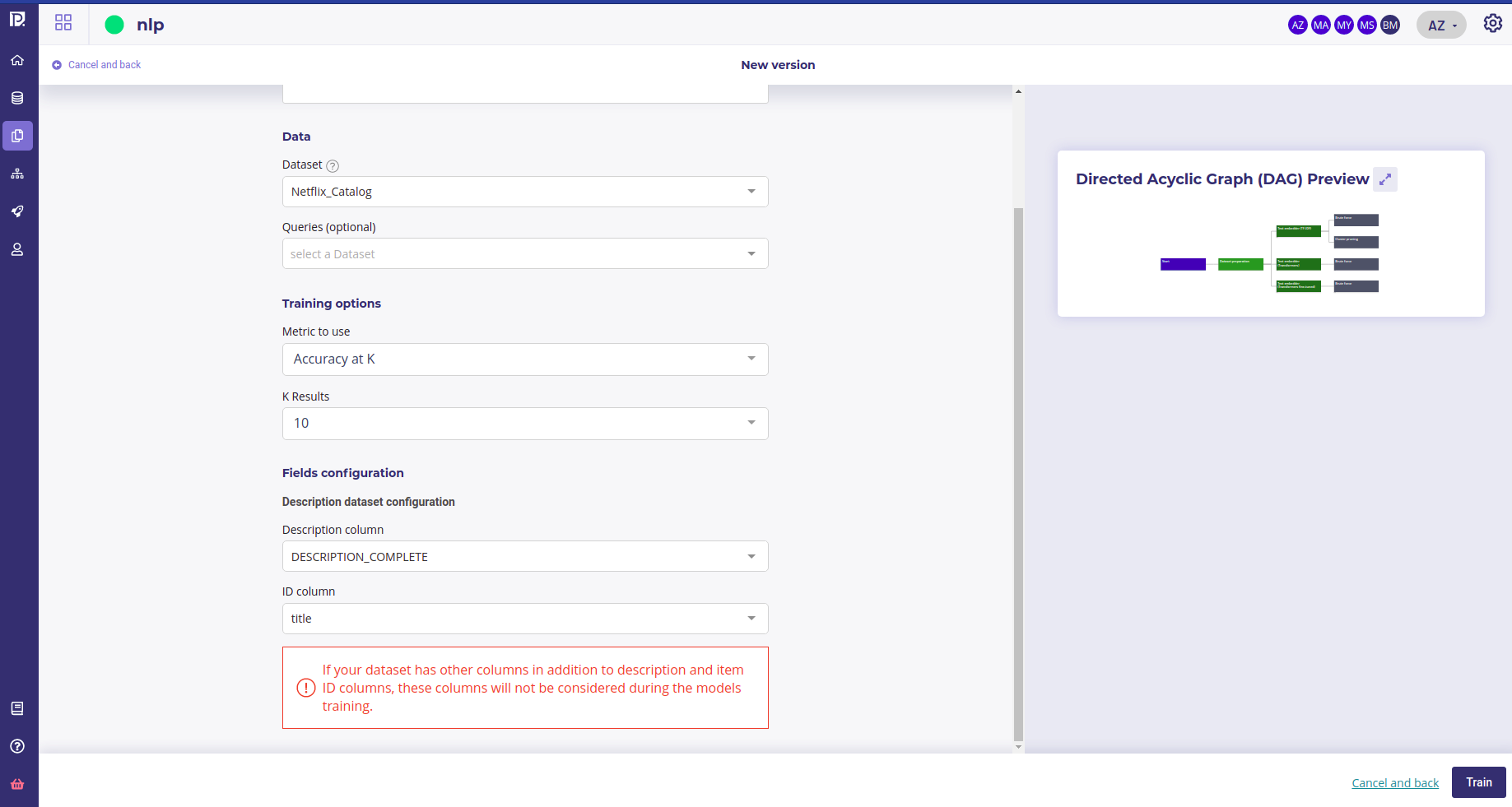
In order to train a text similarity model you must have a trainset ( dataset dropdown menu ) with :
- a description column : some column with text that describes items you want to query (Description column dropdown menu )
- an id column : only column with unique ID could be selected (ID column)
To get better evaluation you should have a query dataset ( queries dropdown menu ) with :
- a textual column containing user queries that should have match with some item description ( query column dropdown menu)
- a column with the id of the item whose description should have match the query (Matching ID column in the description dataset dropdown menu)
Your queries dataset could have its own ID column (ID Column dropdown menu )
Note that the drop down to selet column only appear when you had selected Dataset and/or a Queries
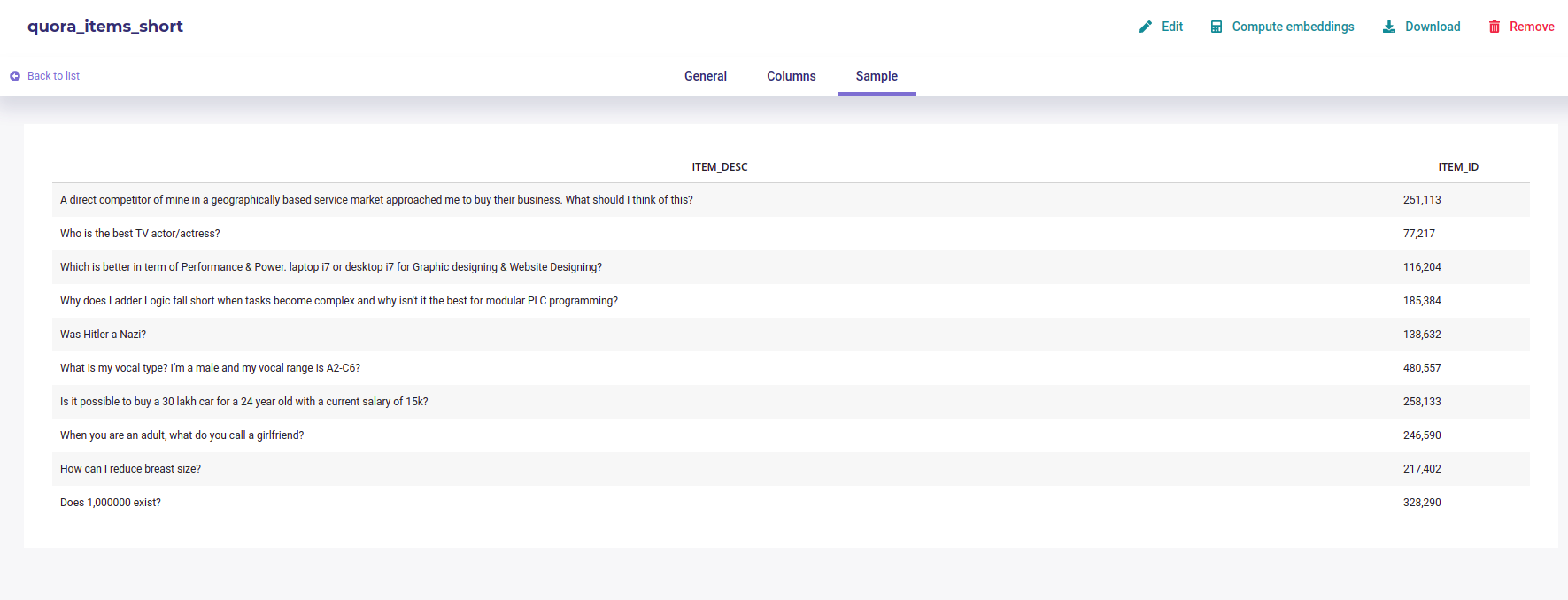
A dataset with items and their description
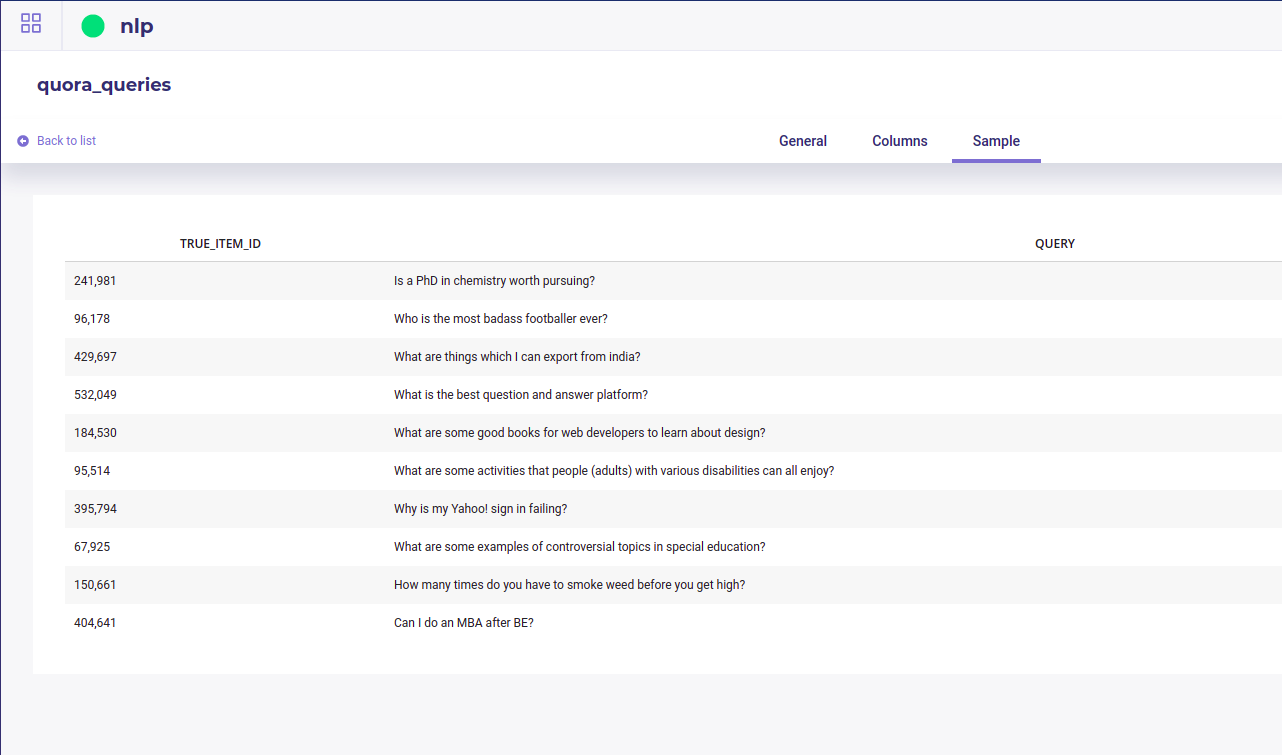
A dataset with user queries and the item id that should have match
You then have to select a metric :
- Accuracy at k: Is the real item corresponding to a query present in the search result, among the k items returned? The value is a percentage calculated on a set of queries.
- Mean Reciprocal Rank (MRR) at k: Similar to accuracy at k. However the score for each query is divided by the rank of appearance of the corresponding item. Example: If for a query the corresponding item appears in third position in the returned list, then the score will be ⅓ . If it appears in second position the score will be ½, in first position the score will be 1, etc. https://en.wikipedia.org/wiki/Mean_reciprocal_rank
- K results : the number of query like items that the tool must return during a search. Value between 1 and 100.
Text similarities models options¶
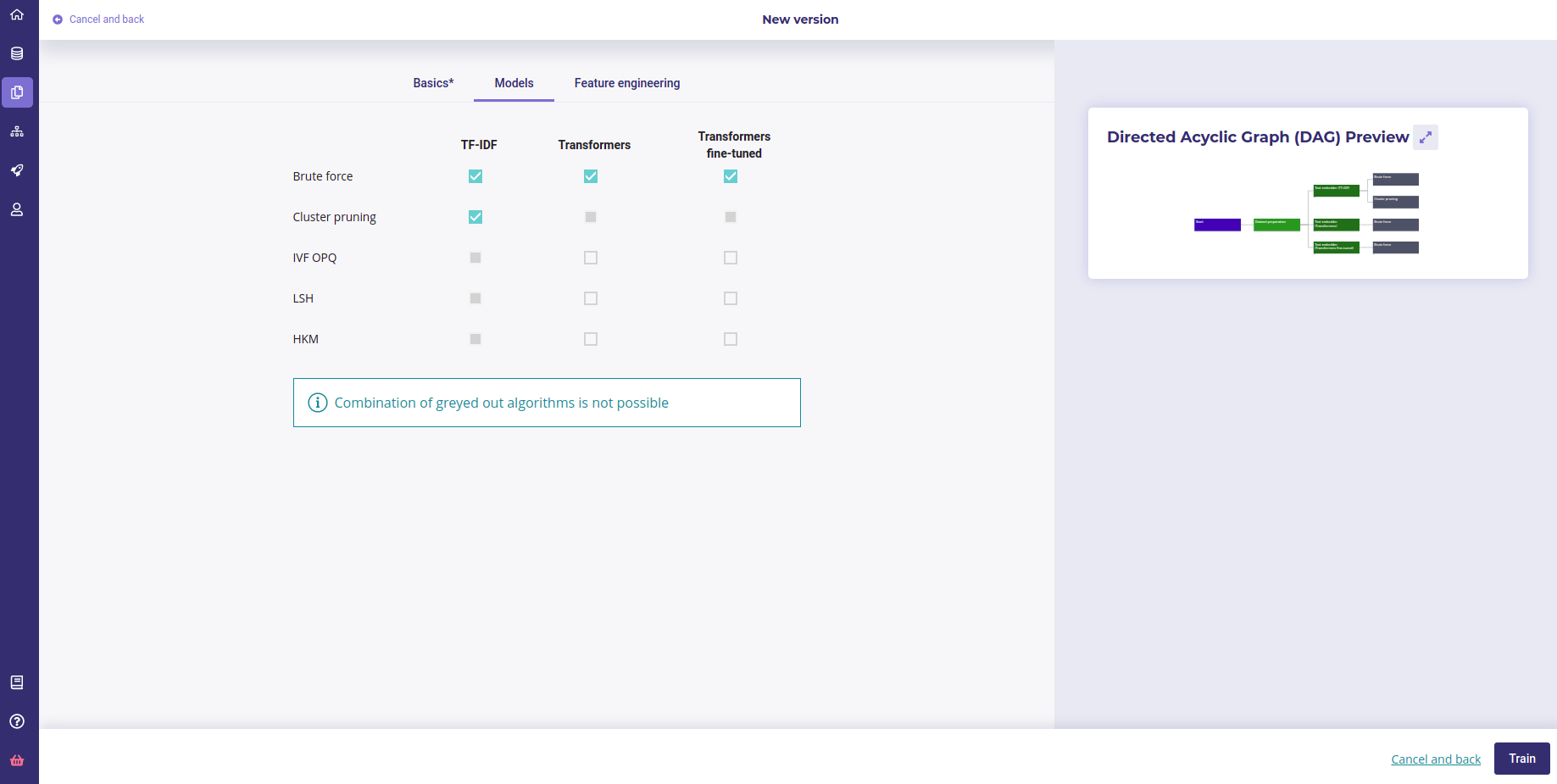
Available algorithm for text similarity models
Text similarity module has its own modeling techniques and is composed of 2 kinds of models :
- embedding model to make a vector representation of your data
- search models to find proximity between your queries and product database
Embedding model / word vectorization¶
Term Frequency - Inverse Document Frequency (TF-IDF): Model representing a text only according to the occurrence of words. Words not very present in the corpus of texts will have a greater impact. https://fr.wikipedia.org/wiki/TF-IDF
Transform: Model representing a text according to the meaning of words. In particular, the same word will have a different representation according to the other words surrounding it. https://en.wikipedia.org/wiki/Transformer_(machine_learning_model)
Transformer feature-based: Transformer that has been trained upstream on a large volume of data, but has not been re-trained on the corpus in question.
Fine-tuned transform: A transform that has been trained on a large volume of data and then re-trained on the text corpus in question.
Search models¶
Brute Force: Exhaustive search, i.e. each query is compared to the set of item descriptions.
Locality sensitive hashing (LSH): exhaustive search. Vectors are compressed to speed up distance calculations. https://fr.wikipedia.org/wiki/Locality_sensitive_hashing
Cluster Pruning: non-exhaustive research. Item descriptions are grouped by cluster according to their similarity. Each query is compared only to the queries of the closest group. https://nlp.stanford.edu/IR-book/html/htmledition/cluster-pruning-1.html
Hierchical k-means (HKM): non-exhaustive research. The idea is the same as for the previous model, but the method used to group the items is different.
InVerted File and Optimized Product Quantization (IVFOPQ): non-exhaustive search. The idea is the same as for the two previous models, but the method used to group the items is different. Vectors are also compressed to speed up distance calculations.
Please note that in order to guarantee the performance of IVF-OPQ models, a minimum of 1000 unique IDs in the train dataset is required.
Text similarity Preprocessing¶
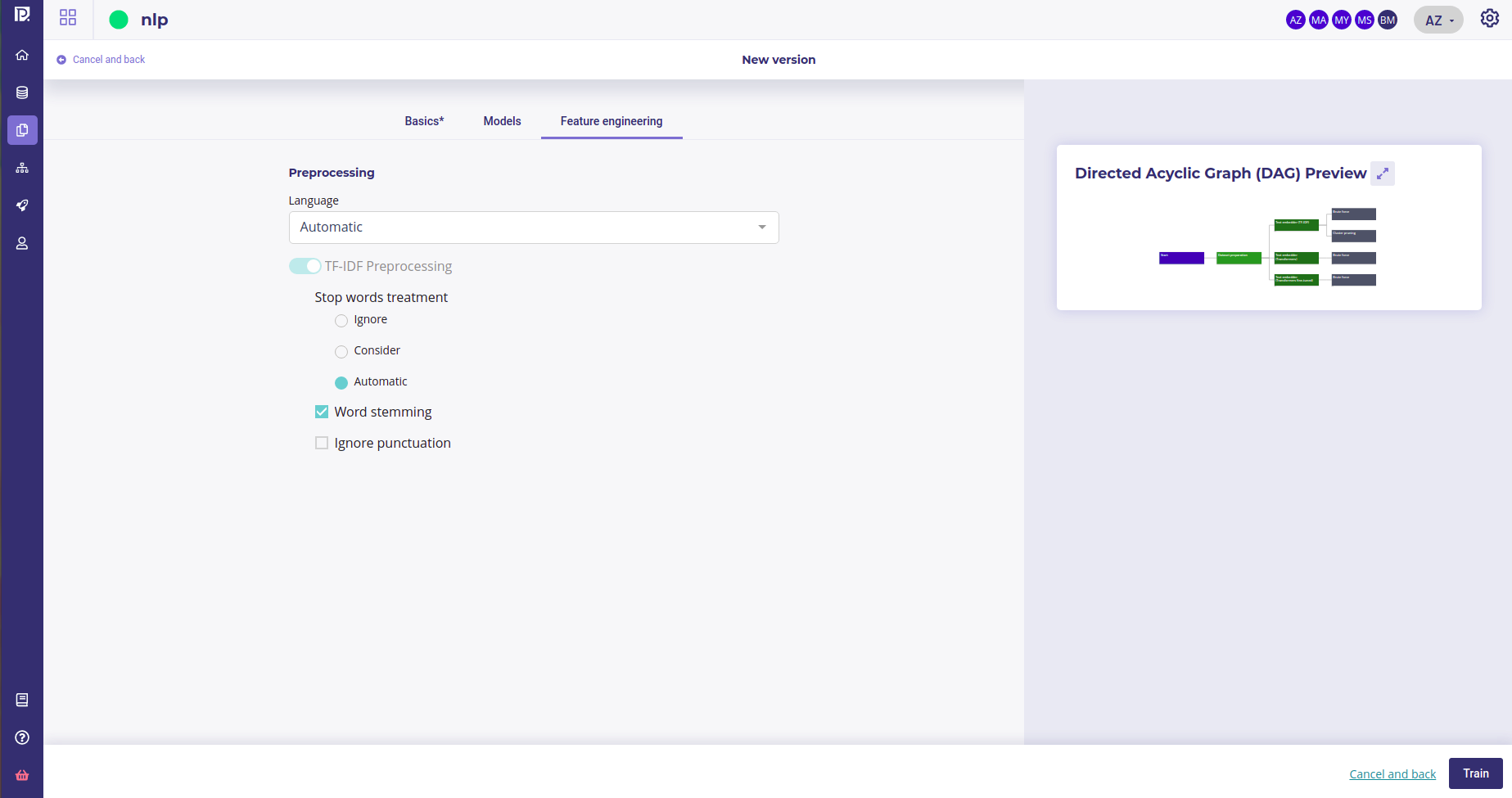
Feature engineering for text similarities
Several preprocessing options are available :
- Language : you can force the training dataset language to english or french or, let the platform determines by itself between these two languages
- Stop words treatment : you can choose if the platform has to ignore or consider the stopwords during the training. As for the language, you can also let the system makes it own decision by selecting “automatic”
- Word stemming : stemming is the process of reducing inflected (or sometimes derived) words to their word stem, base or root form—generally a written word form.
- Ignore punctuation : by activating this option, the punctuation will not be considered during the training
Watching my Text similarity experiments¶
Text similarity experiments will be available in the same way that standard tabular data experiments, by clickin on it the list of your experiments yet it has some specificities.
First one, when you select a model, is the model evaluation chart. It shows the performance evolution along the expected rank
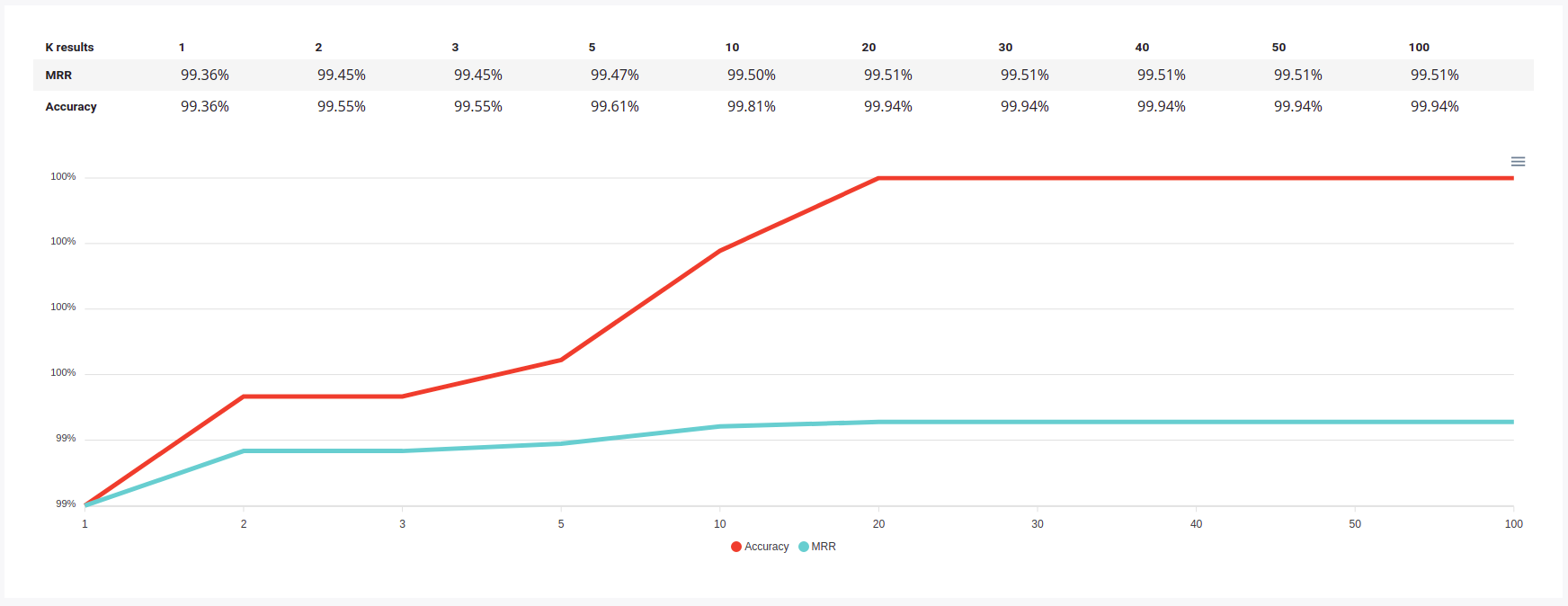
Text similarity models
Second difference is the prediction tab, which is sligthly different from other :
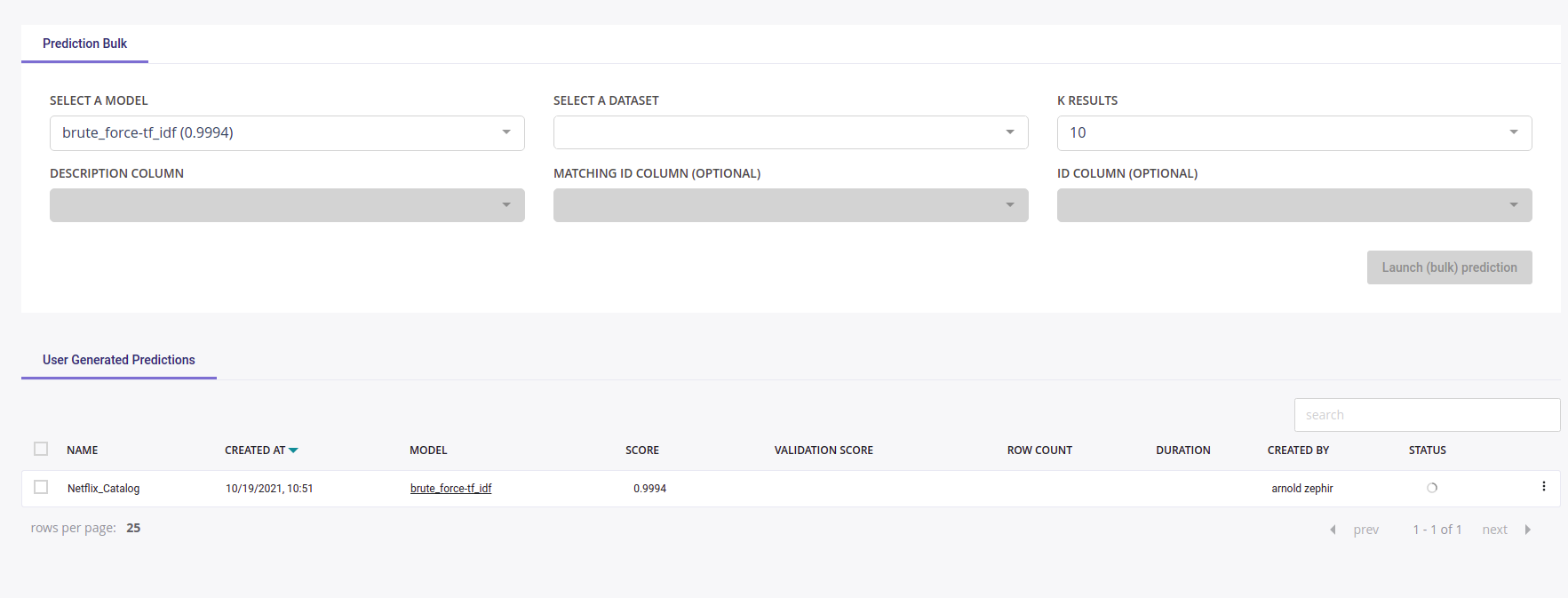
Txt similarity predictions